





DeNA の土屋と申します。2014 年に新卒で入社して以来一貫して IT 基盤部に所属し,現在は第四グループのマネージャーとして,全世界向けに提供している超大規模ゲームタイトルおよびゲームプラットフォームのインフラ運用をリードしています。

IT 基盤部第四グループのメンバー
私のグループでは直近 1 年間,クラウド環境におけるコストコントロールの施策中心に,インフラの QCT (Quality, Cost, Time) マネジメントに取り組んで来ました。その具体的な方法や成果については先日の AWS Summit Tokyo 2019 で発表させて頂きました (以下が発表資料です)。
この資料だけを見ると極めて体系的かつ順調に各施策を進めることができた,ともしかしたら見えるかもしれませんが,実際は様々な試行錯誤がありました。本記事ではそのような苦労話に触れつつ,インフラコスト 60% 削減達成までの道のりについてお話しします。
インフラに求められる QCT とは
インフラノウハウ発信プロジェクト第 1 回目の記事 でも触れられていた内容ですが,具体的な話に入る前にインフラの文脈における QCT がどのような内容を指すかについて改めて整理したいと思います。
- Quality
- 最高品質のインフラを提供することを指します。インフラ起因による障害をなくすことはもちろん,品質維持・向上のためにできることは全て行い,工数の許す限り稼働率 100% を維持し続けることを目指してインフラを運用しています。
- Cost
- インフラ費用を適切にコントロールすることを指します。DeNA のインフラ部隊は創業当時から非常に高いコスト意識を持っています。ただし,ただ安ければ良いという考え方ではありません。管理工数や利便性などに照らしてメリットがあるサービスや商品についてはたとえ割高であっても利用するという判断をします。
- Time (Delivery)
- インフラ提供のリードタイムを短くすることを指します。品質とコストを求めるあまり,インフラ提供までに何ヶ月も掛かるような状態では DeNA の事業展開スピードを支えられません。どのようなスケジュールでも安定したインフラを提供することも重要なミッションの 1 つです。
本記事ではコスト削減がメインの話題になりますが,他二つの水準を落とさないということは大前提になります。
なぜコストコントロールが必要になったのか
DeNA はもともとメインのシステム基盤にはオンプレを採用していましたが,私のグループが担当するサービスは全世界向け,そして必要リソースが大幅に乱高下するため,サービス開始当初から 100% クラウドで運用していました。
そのような中,2018 年 6 月に大きな意思決定がなされます。全サービスのシステム基盤をクラウド化するという決定です。当時の DeNA インフラの概況や,クラウド化の経緯についての説明は以下の資料に譲り,ここでは割愛します。
- オンプレミスに強みをもつDeNAはなぜクラウド化を決めたのか? その舞台裏と今後の展望 - フルスイング
- DeNAのインフラ戦略 〜クラウドジャーニーの舞台裏〜 - DeNA TechCon 2019
オンプレ環境において,DeNA のインフラは圧倒的な低コストを実現していました。これは同一スペックのサーバを同時に大量に購入して調達価格を下げるという工夫や,サーバのリソースを使い切るための技術およびノウハウによるものです。
この状態からクラウド環境へ移行すると費用はどのくらい増えるかを試算したところ,何も工夫せずに移行するとなんと 3 倍にまで膨れ上がるという結果になりました。何も工夫せずと書きましたが,前述のオンプレ環境における技術やノウハウを適用してもなおこのくらい費用が増えてしまうという状況でした。
そこで,このコスト差を埋めるためにコストコントロール施策の実証が必要になった訳です。検討ではなく,実証です。この時点で候補となるような施策はいくつか挙がっていましたが,それらの施策は本当に実現可能なのか,コストは下げられたが品質が劣化することはないか,運用工数が増えることはないか,などの懸念は実際にやってみなければ払拭できません。クラウド移行がすべて完了した後になってやはり実現は無理でした,という事態は何としても避けなければなりませんでした。
システム基盤のクラウド最適化や移行スケジュールの精緻化など,クラウド化の準備として行うべきことは他にもたくさんありましたが,このコストコントロールの実証はすでにクラウドを用いてインフラ運用を行なっている私のグループで担当することになりました。
机上の計算では 50% の削減が可能
クラウドならではのコスト削減はクラウド化の全社決定がなされる前から様々検討はしていました。本腰を入れて進めるにあたり,まずは考えられる手段を列挙し,それらが仮にうまくいった場合に現状のコスト構造に照らしてどの程度のコスト削減が見込めるか,という試算を行いました。その際,阻害要因となるものも一緒に洗い出しています。
例えばオートスケーリング。担当のシステム構成においては,クラウド費用全体の 90% が IaaS の費用であり,その内 60% 程度がオートスケーリングを適用できるサーバでしたので,オートスケーリングによってこれらのサーバの費用が 20% 減らせると仮定すれば全体の費用は 0.90 * 0.60 * 0.20 で約 10% 程度全体の費用を下げられる,というような試算をしました。また,阻害要因としてはオートスケーリングの仕組みを作るための実装コスト,安定して稼働させるまでの導入コスト,またインフラ運用メンバの工数不足などを挙げていました。
他の施策についても同様に試算を行い,全てうまくいった場合 50% の費用削減が可能であるという皮算用を得ました。
ここで重要なのは,もちろんコストを 50% 程度は下げられそうという試算結果も大事なのですが,どの施策から進めるのが費用削減効果と実施工数両方の観点から良さそうか,という優先順位を決めることです。通常のシステム運用をこなしながらこれらの施策を進めていく必要がありましたので,全部を一気に並列に進めることはできません。この優先順位を決めるにあたっては,コスト削減効果の精緻な見積もりよりも (そもそも実際にやってみないと推測の域を出ないので,精緻な見積もり自体不可能),だいたいのオーダ感とどのくらい大変そうかという工数感の方が必要です。
ただし,数値の算出根拠だけはきちんと説明できるようにしておくべきです。先のオートスケーリングの例では 90%,60%,20% という数値が出て来ましたが,90% と 60% は事実なので定数,20% の値は実際のシステムのワークロードに大きく依存するので変数ということになります。こういう説明ができると各施策の勝算の確度が分かるので,優先度を決めるための判断材料の 1 つになりますし,どのくらい未確定要素を含んでいるのか,という認識を関係者間で正しく合わせることにも役立ちます。
オートスケーリングを最優先で導入
コスト削減試算の結果,効果が最も大きかったのはやはり API サーバへのオートスケーリング導入でした。実はオートスケーリングは突発的なトラフィック急騰時のサービス品質への備えとして自動スケールアウト機能だけはすでに導入できていました。また,時間指定の台数の増減もバッチ処理により何とか動いていました。
しかし,これらの既存の仕組みは相当に辛い状態でした。インスタンスの起動,削除,必要台数の計算などオートスケーリングに必要なあらゆる処理が 1 つの巨大なモジュールに全て記述されており,ここに自動スケールインのロジックを追記したり,各処理に対する冪等性担保のための処理やリトライ,エラーハンドリングを入れていくことはもはや不可能でした。台数の自動増減も非常に原始的で crontab に以下のような記述があるだけでした。
0 21 * * * api-server-service-in --ammount 50 # API サーバを 50 台追加
0 0 * * * api-server-service-out --ammount 50 # API サーバを 50 台削除そこで,既存の資産は活用しつつオートスケーリングの仕組みを抜本的に改善することにしました。この改善施策自体はクラウド化が決定する前の段階から進めており,これから本番環境に導入していくというフェーズでした。刷新後のオートスケーリングシステムの設計や実装の詳細は今後の記事で他メンバから紹介してもらおうと考えていますので,この記事では本番に導入していく過程や,今現在どのように運用しているかをお話ししたいと思います。
本番環境で実際に運用するにあたっては,何よりもまずは安定性を重視しました。API サーバはゲームサーバの根幹を担うものであり,これの台数管理を司るオートスケーリングシステムを安定して稼働させることは大前提です。そうはいっても 1 日に数百台というサーバを作っては壊しという作業をひたすら行うため,どこかしらで必ず不具合が出てきます。
そのため,まずは各処理に対してきめ細やかにエラーハンドリングやリトライを入れていきました。例として対象サーバに対して ssh 接続できるか確認する,という処理の設定ファイルの一部を以下に示します。詳しい書式や定義はここでは省略するとしてリトライ間隔,リトライ回数,タイムアウトが指定できるようになっていることがお分かり頂けると思います。
[Task]
Name = "CheckNetowrkSSH"
Description = "check network connection SSH"
[Task.Component.Params]
RetryInterval = 5
Retry = 30
Port = 22
Timeout = 3
また,実際に ssh 接続確認を行うコードは以下の通りで,当然ではありますがきちんとエラーハンドリングを行うコードになっています。
func checkTCP(target string, timeout time.Duration) error {
conn, err := makeConnection("tcp", target, timeout)
if err != nil {
log.Error(
"Failed to make a connection.",
zap.String("protocol", "tcp"),
zap.String("target", target),
zap.Error(err),
)
return err
}
defer conn.Close()
return nil
}
続いて,突発的なトラフィック急騰への対応も必要になります。ゲームサーバというものはイベントの開始・終了のタイミングや,日跨ぎ処理のタイミングでトラフィックがわずか数秒間に 3 倍にまで増えるということが毎日起きます。スケールアウトの高速化の工夫は色々と行いましたが,どれだけに高速化してもサーバ起動からサービス投入までに 3 分は要します。
そのため時間指定でのサーバの増設も必要になります。この機能もバッチ処理ではなくオートスケーリングの機能として折り込みました。現在は以下 (10 分間に 20 台ずつ,計 40 台増設する例) のようにコードで設定を書くようになっていますが,将来的には GUI を用意し,インフラメンバだけでなく開発者やビジネスサイドのメンバにも開放し,事前のキャパシティ増設をワンストップでできるようにしたいと考えています。
launch => {
amount => 40,
time_settings => [
{
from => '05:50:00',
to => '05:59:00',
},
{
from => '06:00:00',
to => '06:09:00',
}
]
}
さて,オートスケーリングの安定化のための工夫をご説明してきましたが,想定外の出来事はどうしても起きます。そういう事態に備えて,オートスケーリングの不具合を早期に検知できるような監視を導入し,問題を検知したらインフラメンバにオンコールで通知することによって 24 時間 365 日即時対応できるような体制を整えています。ここまで至ることは稀ですが,仮に手動対応が必要になったとしても次回以降同じ問題が発生しないようにシステムを改修するということを繰り返し,現時点では相当高品質なシステムに仕上がりました。
最後に実際にオートスケーリングが稼働している様子をお見せします。図 1 からサーバ台数は日々大きく変動していることが分かる一方,図 2 からは CPU 使用率はほぼ一定となるように制御されていることが分かると思います。この結果,最終的に API サーバの費用は 30% 削減することができました。また,これまで手動で台数調整を行ってきましたが,その手間が不要になりましたので運用工数の削減にも大きく寄与しました。
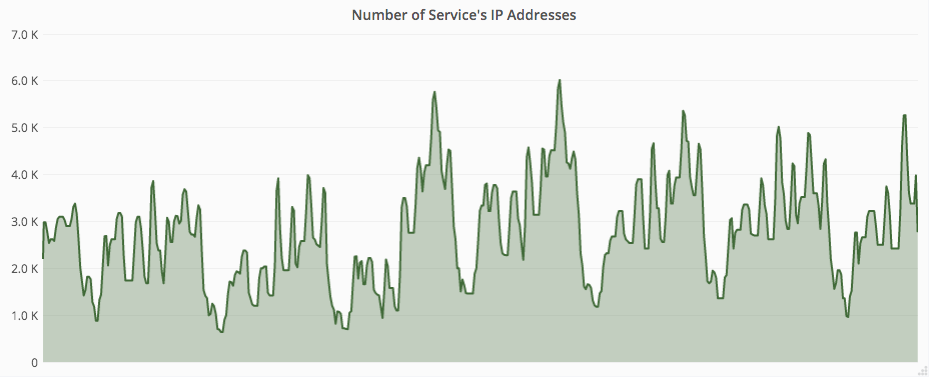
図 1. サーバ台数 (IP Address 数) の推移
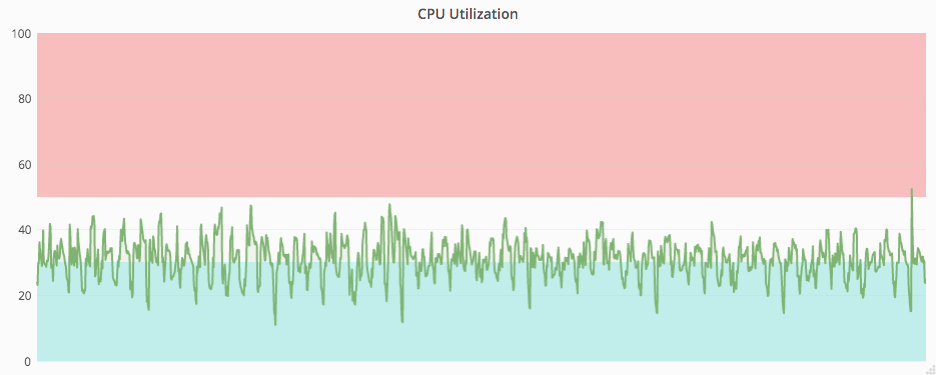
図 2. API サーバ 1 台の CPU 使用率の推移 (赤: スケールアウト水準,青: スケールイン水準)
スポットインスタンスへの挑戦
オートスケーリングの導入に加えて,インスタンスタイプの最新化なども一段落したタイミングで基盤が AWS のシステムにおいてはスポットインスタンス導入を進めていくことなりました。2018 年 8 月の下旬頃から仕様確認や実サービスへの導入方法の検討を本格的に始め,その 2 ヶ月後には実際に運用を開始していましたので,かなりのスピード感で進めていたことがお分かり頂けるのではないでしょうか。
実は計画当初,スポットインスタンスの活用は考慮に入れていませんでした。存在自体は認識していましたが,突然シャットダウンされるという話を聞いただけで,最高品質のインフラを提供するための基盤として利用する選択肢には入れられない,入れられたとしても負荷試験用途やワンショットのバッチ処理などサービスに直接影響が及ばない範囲内で,という考えが正直なところありました。しかし,オンデマンドインスタンスと比較すると非常に安価に利用できるという点はやはり無視できず,このタイミングで俎上に載ってきました。
実際に仕様確認を進めていくと,スポットの中断通知から実際にシャットダウンされるまでの 2 分間で完全にサービスから切り離すことさえできれば,あとは通常のインスタンス故障時の対応を自動化だけで品質を落とすことなく運用に落とし込めるということが分かりました。実際に導入を担当したメンバが「スポットインスタンス は高頻度で故障するインスタンスであると考えれば良い」と話をしていたのが印象的です。
また,オートスケーリングに比べて導入できる対象サーバが多いという点もスポットインスタンスの魅力でした。オートスケーリングの導入対象は,台数が非常に多いこと,負荷の変動が大きいこと,スケーリングの判断基準が明確であること,という大きく 3 つの条件を満たす必要があります。これらを満たさないと十分なコストメリットが得られず,オートスケーリングシステムの管理工数の方がかえって高くつくためです。一方スポットインスタンスであれば,ステートレスなサーバに対しては前述の仕組みさえ整えればコストメリットを得ることができます。最終的には API サーバだけでなく,Cache サーバや非同期処理用の Daemon サーバなどステートレスサーバのほぼ全てに対してスポットインスタンス を導入できました。
インスタンス管理の自動化はオートスケーリングのシステムでほぼできていましたので,2 分以内のサービスからの切り離し処理を教科書通りに実装し,まずは数台実際にサービスに投入してみるというところから導入を開始していきました。
ここから先,スポット率をどう上げていくかというところが一苦労でした。最終的にはセカンダリ IP を活用することで図 3 のように使用するプール数を大量に増やし,安定した運用に落とし込むことができたのですが (詳しくは冒頭の AWS Summit Tokyo 2019 の発表資料にまとめていますので,そちらをご参照下さい),そこに至るまでには様々な試行錯誤がありました。
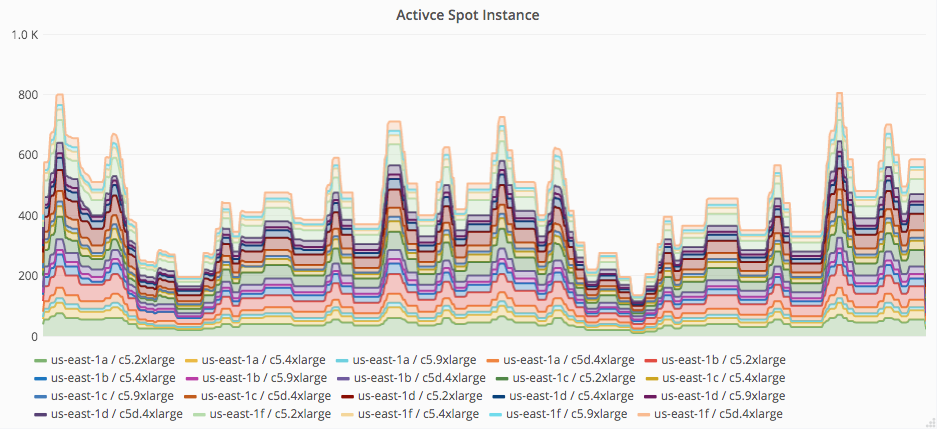
図 3. プールごとのスポットインスタンス数
例えば,異なるインスタンスタイプを混ぜて使うための方法は初めから MyDNS とセカンダリ IP で行こうと決められたわけではありません。インスタンスタイプごとにロードバランサも分け,DNS で重み付けすることよってトラフィックのコントロールを行う方法を検討したり,クラウドベンダに対してロードバランサの重み付けラウンドロビンの機能追加リクエストを出したりもしました。
また技術的な課題だけでなく,スポット率を上げて本当に問題ないかという懸念に対して問題ないと示す必要もありました。幸いにもこのケースにおいてはサービス影響が出る確率を評価することができたため,その定量評価によって関係者全員が納得した状態でスポット率を 100% に設定することができました。リスクの伴う変更を行う際はインフラチームのみの判断ではなく,開発者はもちろん事業部の方々にも十分説明をした上で進めることが重要です。
導入当初は 10% 程度だったスポット率も最終的には 100% まで引き上げることに成功し,ステートレスサーバのコストは 60% 削減することができました。また,スポット中断による障害は起きていないという点も特筆事項だと思います。
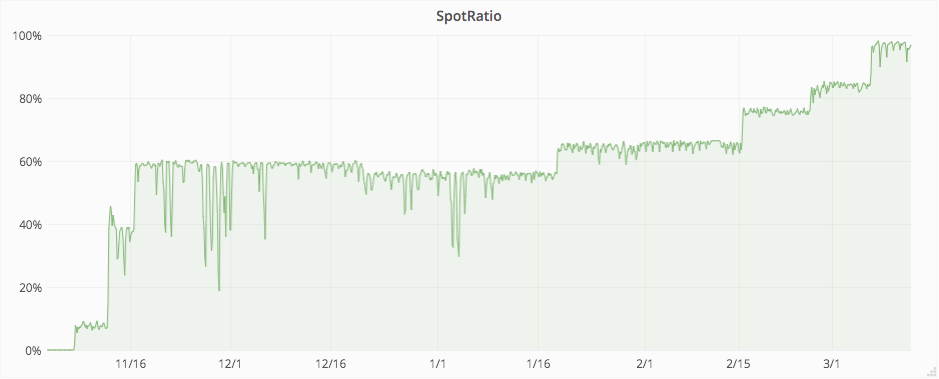
図 4. スポットインスタンス使用率の推移
DB サーバの QCT マネジメント
DeNA が DB サーバとして MySQL を使用していることはご存知の方も多いと思いますが,クラウドにおいても変わらず MySQL を利用しており,なおかつマネージドサービスではなく IaaS 上に MySQL を立てて運用しています。ここでは DB サーバに対する施策について,ゲームサーバにおける DB サーバの負荷傾向について触れながらご説明します。
DB サーバはゲームのリリース当日から数週間程度 CPU,I/O ともに負荷が高い状態となりますが,特に書き込みがボトルネックになり,これをきちんと捌けるかどうかが安定リリースの要となります。この高負荷に対応するため,DeNA ではシャーディング (水平分割) を多用します。タイトルの規模感に合わせて調整しますが,多いものだとシャード数は 3 桁に及びます。また読み込みのスケーラビリティ確保のために,シャーディングされた DB はそれぞれ master-slave 構成を組んでいます。
一方,リリースからしばらく時間が経つとアクティブユーザの数がリリース当初よりは落ち着いてくるため,CPU 負荷も下がっていきます。他方,データは溜まり続けるため,I/O がボトルネックになるという傾向は変わりませんし,ディスクのサイズがネックになることもあります。
このようにリリースフェーズとその後の運用フェーズで大きく負荷傾向が変わってくる DB サーバの運用は非常に難しいです。ステートレスなサーバと違い,単純な台数調整やスペック調整を行うことが難しいからです。特に難しいのがシャーディングした DB のシュリンクです。一度シャードを広げてしまうと,その後の縮小は容易ではありません。しかし,容易ではないからといって放置するわけにもいきません。大量のシャードを運用し続けると膨大な費用が掛かります。したがってシャードの集約が必須になると同時に,どの程度までシャードを集約できるかがそのまま DB サーバのコストコントロールの成果に繋がります。
シャード集約におけるポイントは 2 つあります。
1 つ目は I/O 性能です。シャードを集約していくわけですから,例えば 2 つのシャードを 1 つに集約したら単純に I/O は 2 倍に増えるということになります。ただでさえ I/O がボトルネックであるのに,集約によってその傾向に拍車がかかるため,当然集約後のサーバに対しては高い I/O 性能が求められます。ネットワークストレージをマウントしたインスタンスではこの I/O を捌くのは難しく,私たちはローカルストレージを持つインスタンスを採用することにしました。AWS であれば i3 あるいは i3en インスタンスが,GCP であればローカル SSD をマウントしたインスタンスがこれに相当します。
ローカルストレージは高い I/O 性能を得られる一方で,インスタンスを再起動したり,インスタンス障害などでインスタンスが止まってしまうとデータが全て消えてしまいます。まさに諸刃の剣です。この問題に対しては,データを 4 重に持つことで対応することにしました。すなわち master 1 台に対して slave は必ず 3 台以上用意するということです。また,万一の自体に備えて MySQL のフルダンプを毎日取得し,クラウドストレージへ保存するという仕組みも整えています。
さて,高い I/O 性能は確保できたので次は 2 つ目のポイントである集約方法について考えていきます。普通にシャード集約を行うことを考えると,あるシャードに対して別なシャードのデータを流し込むというのが一般的な方法だと思います。実際に DeNA でも過去この方法を取っていたことがありました。しかしこの方法ではサービスの長時間の停止を伴うメンテナンスが必須になります。他の目的で実施されるメンテナンスに合わせて実施すれば良いと考えられる方もいらっしゃるかもしれませんが,データの流し込みには何時間も要するため,結局シャード集約のためにメンテナンス時間を延長する必要があります。
そこで私たちは 1 つの MySQL プロセスに対してデータを集約していくという方法は諦め,1 台のインスタンスに複数の MySQL プロセスを立てるという構成を取ることでシャード集約を実現しました。この方法は 1 台の物理サーバの性能を使い切るための方法としてオンプレ環境でも多用しています。
まずは 1 台のインスタンスに複数のプライベート IP アドレスをアタッチします。
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:E1:0C:0A:6E:8A
inet addr:10.228.155.252 Bcast:10.228.155.255 Mask:255.255.252.0
inet6 addr: fe80::e1:cff:fe0a:6e8a/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
RX packets:1999977249 errors:0 dropped:0 overruns:0 frame:0
TX packets:4789699563 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2036044138753 (1.8 TiB) TX bytes:6290789751880 (5.7 TiB)
eth0:ae49853 Link encap:Ethernet HWaddr 02:E1:0C:0A:6E:8A
inet addr:10.228.152.83 Bcast:10.228.155.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
eth0:ae49922 Link encap:Ethernet HWaddr 02:E1:0C:0A:6E:8A
inet addr:10.228.153.34 Bcast:10.228.155.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
eth0:ae49af9 Link encap:Ethernet HWaddr 02:E1:0C:0A:6E:8A
inet addr:10.228.154.249 Bcast:10.228.155.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
eth0:ae49bd4 Link encap:Ethernet HWaddr 02:E1:0C:0A:6E:8A
inet addr:10.228.155.212 Bcast:10.228.155.255 Mask:255.255.252.0
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1次に,各プロセスに対する MySQL の設定ファイルを用意し,以下のようなスクリプト (実際に私たちが使っているスクリプトを簡略化して記載) で MySQL プロセスを起動します。
sub start_mysql {
my ($hostname, $mysqld_opts) = @_;
my $pid = fork();
unless ($pid) {
close STDIN;
close STDOUT;
close STDERR;
exec "/usr/bin/mysqld_safe --defaults-file=/etc/my-$hostname.cnf $mysqld_opts &";
exit;
}
}
すると以下 (ps auxf の結果を整形) のように複数の MySQL プロセスが起動している状態になります。
root /bin/sh /usr/bin/mysqld_safe --defaults-file=/etc/my-ae49853.cnf
mysql \_ /usr/sbin/mysqld --defaults-file=/etc/my-ae49853.cnf --basedir=/usr --plugin-dir=/usr/lib64/mysql/plugin --user=mysql ...
root /bin/sh /usr/bin/mysqld_safe --defaults-file=/etc/my-ae49922.cnf
mysql \_ /usr/sbin/mysqld --defaults-file=/etc/my-ae49922.cnf --basedir=/usr --plugin-dir=/usr/lib64/mysql/plugin --user=mysql ...
root /bin/sh /usr/bin/mysqld_safe --defaults-file=/etc/my-ae49af9.cnf
mysql \_ /usr/sbin/mysqld --defaults-file=/etc/my-ae49af9.cnf --basedir=/usr --plugin-dir=/usr/lib64/mysql/plugin --user=mysql ...
root /bin/sh /usr/bin/mysqld_safe --defaults-file=/etc/my-ae49bd4.cnf
mysql \_ /usr/sbin/mysqld --defaults-file=/etc/my-ae49bd4.cnf --basedir=/usr --plugin-dir=/usr/lib64/mysql/plugin --user=mysql ...後は集約前の master から上記で起動した MySQL プロセスに対してレプリケーションをつなぎ,master を切り替えていくだけです。DeNA では MHA を利用して MySQL の master 切り替えをオンラインで実施できるようにしていますので,メンテナンスなしでのシャード集約が可能です。
この方法を用いることで,DB サーバの数を最大 75% 削減することに成功したタイトルもありました。また,メンテナンスなしでシャード集約を行える方法が確立したことで,今後はリリース初日は DB サーバに十分なキャパシティを持たせるためにあえて最初から数百から数千のシャードを用意しておき,負荷の様子をみながら無停止でシャードを集約していくという運用が可能になりました。
これまでは DB サーバのシャード集約の難しさや維持コストの高さから,必要最低限のシャード数でリリース当日を迎えることがほとんどでしたが,こうしてしまうと万一予想を上回るトラフィックが押し寄せてしまった場合は長期間の障害は免れませんでした。したがって,今回ご説明した運用方法は超大規模ゲームタイトルの安定リリースに大きく貢献し,なおかつコストも速やかに削減することができる非常に優れた方法であると言えると思います。
最後に
今回は主にオートスケーリング,スポットインスタンス,DB サーバの運用に焦点を当ててこの 1 年間の取り組みについてご紹介させて頂きました。QCT 全てを高い水準で満たすために様々な工夫をしているというところを少しでも感じ取って頂けましたら幸いです。技術的な詳細はかなり省略した箇所もありましたが,その内容については今後他メンバからご紹介させて頂く予定ですので,もっと具体的な話にご興味をお持ちの方は引き続き本ブログをご覧下さい。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。