





はじめに
皆さんこんにちは。DeNA AIシステム部の李天琦(leetenki)です。 DeNAのAIシステム部では、物体検出、姿勢推定、アニメ生成等、様々なComputer Vision技術の研究開発に取り組んでいます。また、AIシステム部では世界の最新技術トレンドにキャッチアップするために、年一回国際会議に自由に参加できる機会が設けられています。 今回は、アメリカ ロングビーチで開かれたComputer Visionに関する世界トップの国際会議の一つである「CVPR 2019」に、AIシステム部コンピュータビジョンチームのメンバー7名 (加藤直樹、葛岡宏祐、洪嘉源、鈴木智之、中村遵介、林俊宏、李天琦)で参加してきましたので、その内容について紹介したいと思います。また、今回は聴講としてだけでなく、DeNAからコンペ入賞も一件あり、DSチームの加納龍一と矢野正基の2人が発表してきたので、その様子についても紹介したいと思います。なお、今回のレポートは加納龍一、洪嘉源、林俊宏、矢野正基、李天琦の5名で協力し執筆しています。

CVPR2019とは
CVPRの正式名称は「Computer Vision and Pattern Recognition」で、ECCV、ICCVと並ぶComputer Vision分野における世界三大国際会議の一つです。ちなみにComputer Visionというのは人間の視覚をコンピュータを用いて表現することを目指した技術分野で、画像や映像認識技術全般を指しています。そのComputer Visionの分野において世界三大国際会議の一つがこのCVPRです。そして近年ではDeep Learningを始めとするAI技術の飛躍的な進歩により、あらゆるComputer Vision分野でDeep Learningを使うことが当たり前になってきているので、CVPRでもDeep Learningの手法を応用した論文が大半を占めるようになりました。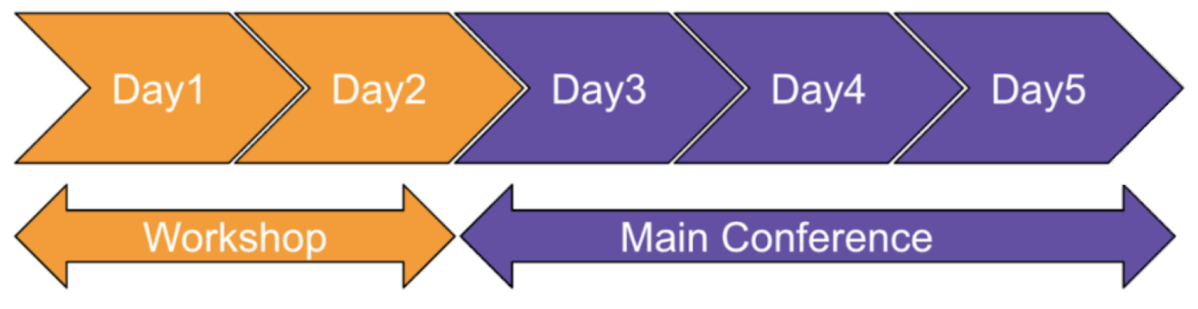
今年の開催期間は6/16〜6/20の5日間です。最初の2日は特定のテーマに絞ったTutorial & Workshopで、後半の3日間がMain Conferenceです。また、Main Conferenceの3日間では、Expoと呼ばれるスポンサー企業の展示会も並行して行われ、世界をリードするIT企業の最新の研究成果や製品などが展示されました。
開催場所
今年の開催場所はアメリカカリフォルニア州のロングビーチで、Long Beach Convention & Entertainment Centerという、北アメリカ最大級のイベント施設を貸し切って会議が開かれました。会場の立地も良く、ロングビーチの海が一望できる最高のリゾート地でした。
参加統計
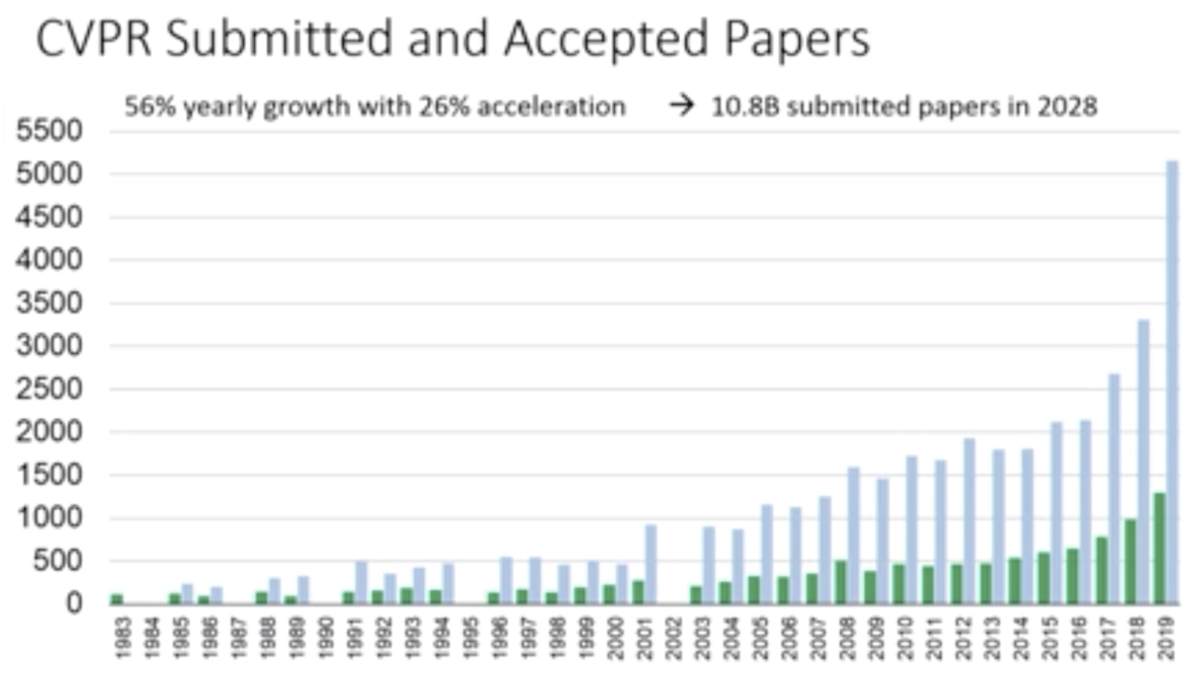
近年AI技術への注目の高まりを受けて、CVPR参加者は年々増加し、今年は参加者も採録論文数も過去最高となりました。統計によれば、今年の投稿論文数は5160本で、採録論文数は1294本でした。そして今回のCVPR参加人数は9227人と、CVPR 2018の時と比べて1.5倍以上にものぼっています。ここ数年の増加率があまりにも高すぎて、「このまま増え続ければ2028年には投稿論文数100億本になる」と主催者も冗談交じりに話していました。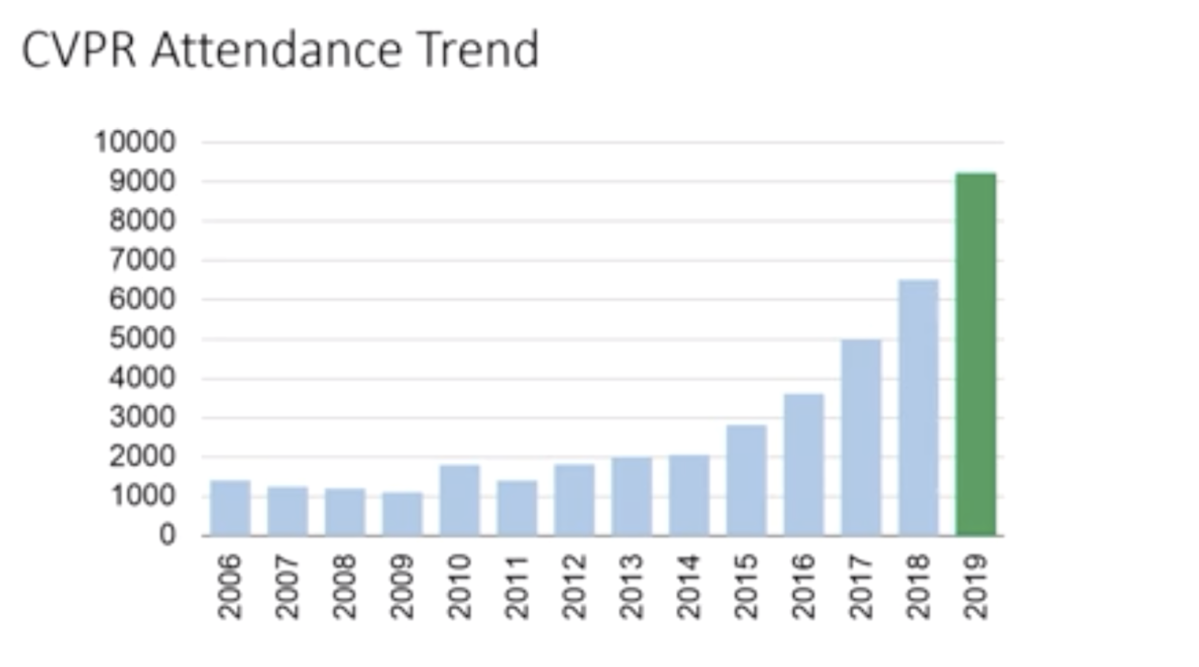

セッションの様子
CVPRに採録された論文のうち、評価の高かったものはOralと呼ばれる口頭発表形式のセッションで発表されます。例年であれば、論文の内容に応じて発表時間が長いLong Oralと短いShort Oralに更に分割されますが、今年は論文数があまりにも増えすぎたために全て発表時間5分のShort Oralとなりました。また、Oralを含めた全採録論文はPosterセッションで展示され、そこでは著者と直接ディスカッションを行うことができます。
ネットワーキングイベント
Main Conference期間中、初日の夜に立食形式の「Welcome Dinner」と、2日目の夜に「Reception Party」という2つの公式ネットワーキングイベントが開催されました。Reception Partyでは、会場付近のEntertainment Centerを貸し切ってのお祭りが行われ、世界各国の研究者達と親睦を深めることができました。
キーワード分析
今年採録された論文のタイトルから、頻出キーワードを抽出してみたところ、以下の結果となりました。特に3Dや、Detection、Attentionなどを取り扱った論文が多いことがここから読み取れます。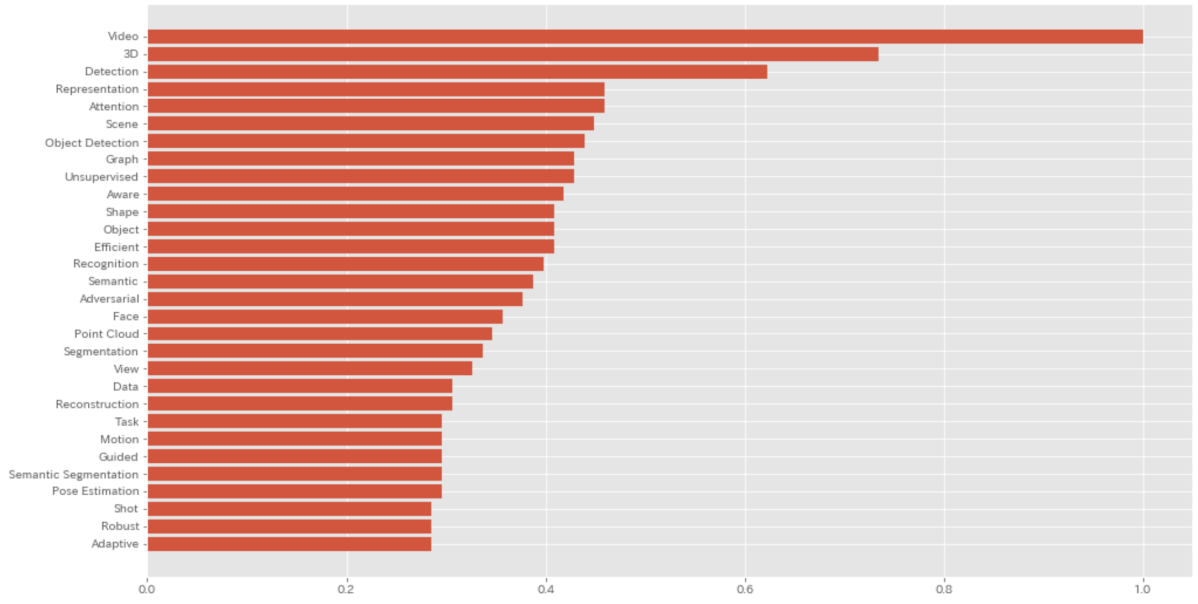
これ以外にも、現地で実際によく目についたキーワードとして、unsupervised、 self-supervised、 weakly-supervised、few-shot、zero-shot、NAS(Neural Architecture Search) 、adversarial examples等が多い印象でした。 実際にCVPR2013〜CVPR2019の7年間で、各年の採録論文数全体に対するキーワードを含む論文数の比率をグラフ化してみました。確かに○○supervisedや○○shotといった、データやアノテーションが限定された問題設定の論文が全体的に増加傾向にあることがここから見てわかります。
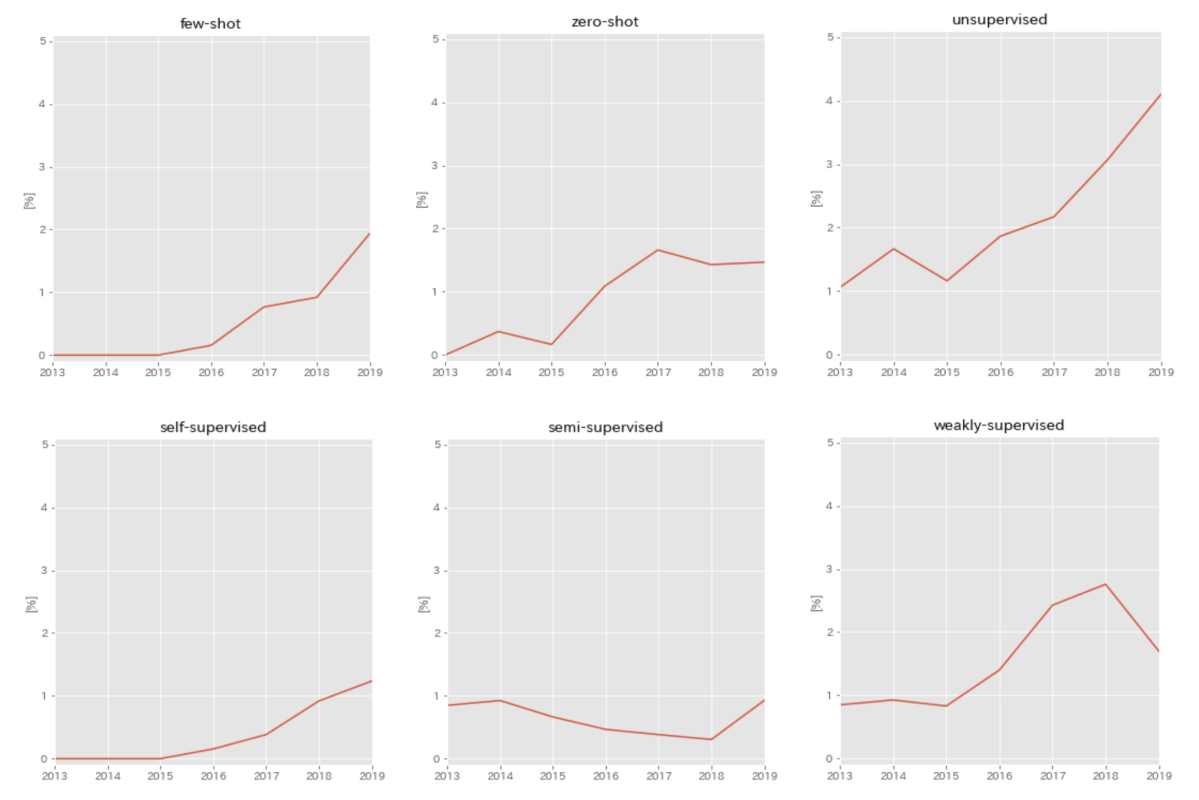
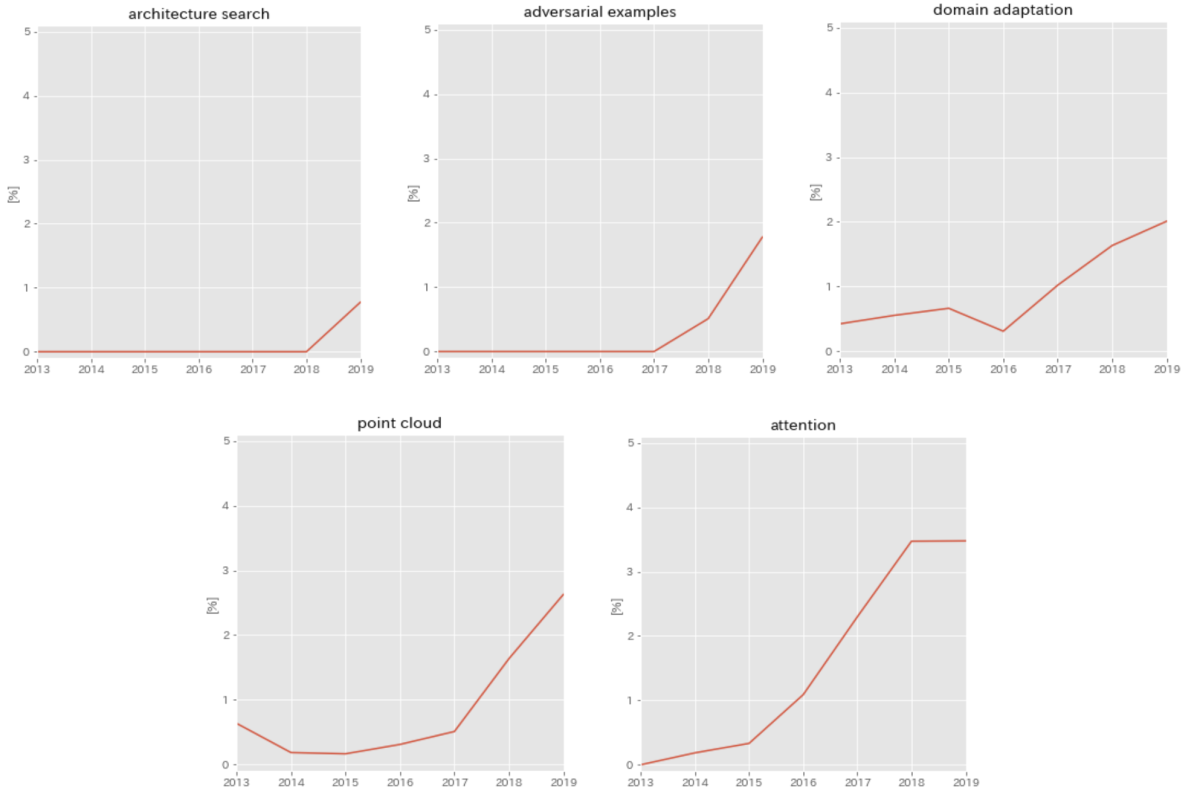
同様に、ネットワーク構造を自動で探索するArchitecture search系の論文や、なんらかのモデルを騙すための攻撃 & 防御を扱ったadversarial examples等の論文も増加傾向にあることがわかります。その他にもいくつか増加傾向にあるキーワードを下図に示します。
受賞論文
今回CVPR2019で発表された論文の中で、受賞されたものをいくつか紹介します。A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction
まず、CVPR2019 Best Paperに選ばれたのが、こちらの"A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction" (Shumian Xin et al.) です。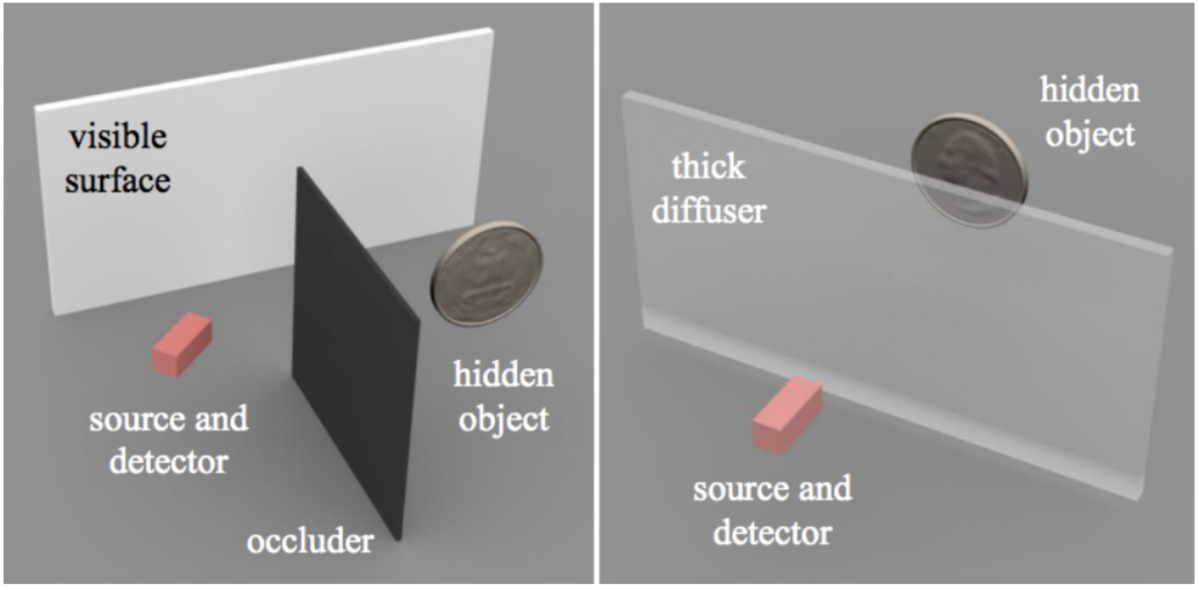
Non-Line-of-Sight(NLOS)物体というのは、カメラなどの視界に直接映らない(撮影できない)物体のことを指します。それらのNLOS物体に対して、周辺環境での反射などを利用して画像化や形状復元する技術をここでは扱います。例えば、曲がり角の向こうにある物体を見ることや、厚い分散媒質を通して物体を透視することなどがこれに当てはまります。NLOS技術は、自動運転、遠隔センシングや医用画像処理など様々なシーンで応用することができるため、コンピュータビジョン領域でも徐々に注目を集めています。今回のCVPR2019では、NLOS に関する論文はBest Paperを含めて6本も採録されています(Oral: 3, Poster: 3)。

この論文ではNLOS物体を測定するために、高速変調光源と時間分解センサー(time-resolved sensors)を使用しています。時間分解センサーは光子の数とカメラに到達する時間を測定することができ、トランジェントカメラ(transient camera)と呼ばれます。NLOS物体からの光子を直接トランジェントカメラで観測することはできませんが、付近の可視表面で反射した光子を受信することで、その不可視の物体を探知することが可能になります。この論文では、可視表面とNLOS物体の間の光のフェルマーパス(Fermat paths of light)に関する理論を提唱しています。著者のXinらは、フェルマーパスがトランジェント測定値の不連続点と対応することを証明しました。さらに、これらの不連続点が対応するフェルマーパスの長さの空間微分とNLOS物体表面の法線と関連する制約条件を導き出しています。これに基づいて、視線範囲外の物体の形を推測するアルゴリズムFermat Flowを提案し、初めて幾何的な制約条件だけを利用して精確にNLOS物体の3D表面を復元することに成功しています。
Learning the Depths of Moving People by Watching Frozen People
次はHonorable Mentionを受賞した2本の論文のうちの1つである"Learning the Depths of Moving People by Watching Frozen People" (Li, et al.) を紹介します。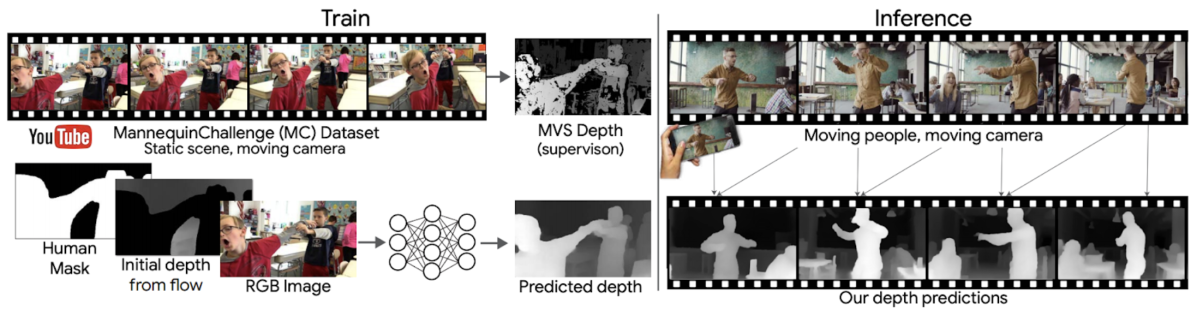
こちらの論文ではRGB入力からの人の深度推定を扱っています。Kinectのようなデバイスは屋外では使えないということもあり、これまで様々な姿勢・シーン・年齢などをカバーした大規模データセットはありませんでした。この論文では、2016年後半からYouTubeで一大ブームになったマネキンチャレンジの動画に着目して、それら約2,000本の動画から大規模データセットを構築し、それを使ってモデルを学習しています。ちなみに、マネキンチャレンジというのは人が様々なポーズをした状態でマネキンのように静止し、そこをカメラが移動しながら撮影するというものです。マネキンチャレンジの動画では人を静止物として扱えるため、SfM (Structure from Motion), 及び MVS (Multi-View Stereo) の技術により人の深度を推定でき、それを教師としたデータセットを構築できます。最終的に学習されたモデルの性能も素晴らしいですが、それ以上にマネキンチャレンジ動画に目をつけてデータセットを作るというアイディアが光っており、とても興味深い論文です。
A Style-Based Generator Architecture for Generative Adversarial Networks
最後は、Honorable Mentionを受賞した2本の論文のうちのもう1つである “A Style-Based Generator Architecture for Generative Adversarial Networks” (Tero Karras, et al.) を紹介します。
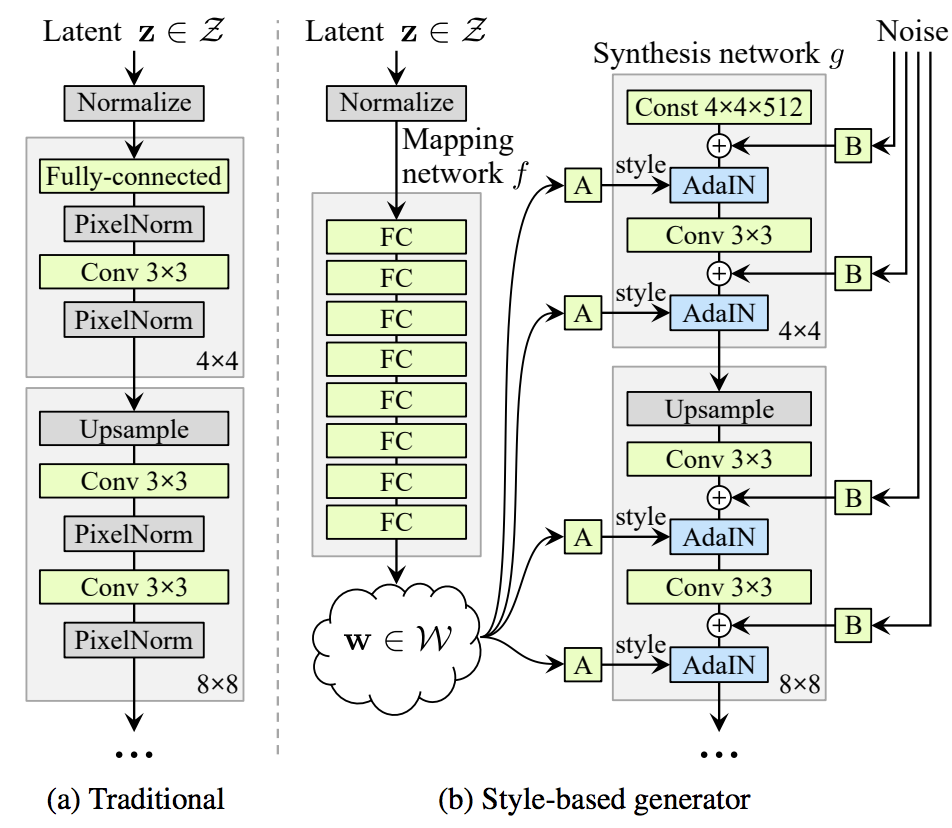
こちらの論文は1024×1024の高解像度な画像生成を扱ったものです。Style-Transfer等でよく使われるAdaINのアイデアを取り入れることで、より制御しやすく、狙った生成を可能にしています。本論文の著者であるTero Karrasさんは、先行研究として以前にICLR2018でPGGAN (Progressive Growing of GANs) を発表しています。そちらの論文では、GANの生成学習において、段階的にネットワーク層を増加させ、生成画像の解像度を徐々に上げていくことで、安定的に高解像度な生成を実現しています。本論文はその基礎の上で、更にGenerator部分に工夫を施し、潜在表現ベクトルzをGeneratorの最初ではなく、Mapping Networkを通じてAdaINのパラメータとしてネットワークの途中途中に埋め込んでいます。 解像度ごとに異なる潜在ベクトルzを埋め込むことで、coarse(姿勢、顔の形)、middle(髪型、目)、fine(髪質、肌色)といった、異なるレベルのstyleを分離して制御できるようになっています。また、上記AdaINとは別に、ランダムノイズを各特徴マップに足し合わせることで、生成画像の確率的な要素(髪の流れ方や肌のシワ等)の操作を可能にしています。

このような高解像度な画像生成を、教師なし学習で、かつStyleを制御可能にできたことが本論文の最大のContributionです。
DeNAのPoster発表
今回、Tutorial & Workshopと並行して開催された、「iMet Collection 2019」という美術品の画像識別コンペにて、DeNAのDSチームから加納龍一と矢野正基の2人が参加し、金メダルを獲得することができたので、Poster発表を行いました。
こちらのコンペでは、ニューヨークのMetropolitan美術館でデジタル化されている約20万枚の美術品の画像を用いて、作品の内容や文化的背景などの観点からつけられたタグ付けを予測する多クラス分類問題の精度が競われます。今回金メダルを受賞したDeNAの加納龍一と矢野正基のチームでは、Pseudo labelingやBlendingといった従来のコンペで実績を残している手法に加え、CVPR2019に採録されたAttention Branch Networkという新しい技術を導入していくことで、金メダルを獲得することができました。
全体の感想
今回、DeNA AIシステム部から7名でCVPR2019に参加し、各自のスペシャリティを活かした効率的な情報収集を行いました。今回発表されたOralプレゼンテーションは全て、こちらのYouTubeチャンネルでも公開されていますが、実際に現地に行くことで論文の気になる点を作者に直に聞けたり、ネットワーキングもできる等のメリットがあります。自分は今年で3度目となるCVPR参加ですが、技術的な収穫はもちろん、ネットワークも広がって凄く良い刺激になりました。また、今回のEngineer Blogとは別に、現地に参加したメンバーで、注目度の高い論文や有益性の高いと判断した論文30本を厳選し、解説資料 (Slide Share) にまとめて公開しましたので、興味ある方はそちらも合わせてお読みください。
DeNA CVチームでは引き続き調査を継続し、最新のコンピュータビジョン技術を価値あるサービスに繋げていきます。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。