





はじめに
こんにちは、AIシステム部でコンピュータビジョンの研究開発をしております本多です。
我々のチームでは、常に最新のコンピュータビジョンに関する論文調査を行い、部内で共有・議論しています。今回我々が読んだ最新の論文をこのブログで紹介したいと思います。
今回論文調査を行なったメンバーは、洪 嘉源、林 俊宏、本多 浩大です。
論文調査のスコープ
2018年11月以降にarXivに投稿されたコンピュータビジョンに関する論文を範囲としており、その中から重要と思われるものをピックアップして複数名で調査を行っております。今回はHuman Recognition編として、ポーズ推定をはじめとする人物の認識に関する最新論文を取り上げます。
前提知識
今回紹介するHuman Recognitionとは、RGB画像を入力として、人物の姿勢推定やセグメンテーション、モーションキャプチャ情報を推定するタスクです。複数人物の映った画像に対して上記のタスクを行う場合、各人物の領域を検出してから、各人物の器官点などの認識を行うTop-down手法と、画像中の全領域から器官点などを検出してから人物ごとにグループ分けするBottom-up手法に分類されます。今回紹介する論文の手法はTop-down手法または単一の対象に対する手法となります。
Human Recognitionには以下のようなタスクがあります。
- Pose Estimation(姿勢推定):人物の器官点(目・肩・ひざなど)の位置を推定するタスク。
- Dense Human Pose Estimation :人体3Dモデルとの対応点を密に推定するタスク。
- Markerless Motion Capture:マーカーを使わず、画像のみからモーションキャプチャ情報を推定するタスク。
- Human Parsing:人物の髪・顔・腕など、身体パーツでセグメンテーションするタスク。
関連する主なデータセットは以下です。
- MS-COCO 物体検出・セグメンテーション・人物姿勢等のラベルを含むデータセットで、recognition系のタスクではデファクトスタンダード。
- MPII, PoseTrack 人物2D姿勢データセット。
- DensePose 人物3Dモデル対応点データセット。
- Human3.6M 人物3D姿勢データセット。
- MHP Human Parsingデータセット。
- STB 手の3D姿勢推定データセット。
論文紹介
CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark (CVPR2019 Oral)
要約
人物が重なりあった混雑シーンに対応できるポーズ推定手法と、混雑度をコントロールしたCrowdPoseデータセットの提案
提案手法
ポーズ推定手法
- 人領域 (bounding box) の検出器としてYOLOv3 (*1) を用い、それぞれのbox内のポーズ推定はsingle-person pose estimator(SPPE, 単一人物姿勢推定)で行い、高性能な従来手法であるAlphaPose (*2) を修正して使用。
- AlphaPoseでは、人検出器で画像の中に各人物の領域 (ROI) を検出した後、その人に属する関節点のみを正解関節点としてロスを計算する。本論文では、各人物の領域 (ROI) に対して、その人物に属するかどうかを問わず、ROI内に存在する全ての関節点を正解関節点として、Joint-candidate Lossを計算する。全ROIの関節点を入力画像にマッピング、距離が近い同種類の関節点をクルーピングし関節点ノードとする。これによって、2で重複して検出された関節点を一つのノードとしてまとめる。
- 全ての関節点ノードをGlobal Associationステップで各人物のノードに割り当て、統合する。これにより、画像全体の視点から各人の関節点をより正確に割り当てることができる。
CrowdPoseデータセット
CrowdPoseという混雑シーンのポーズ推定用データセットを作成した。20000枚の画像からなり、80000の人物を含み、混雑度を示すCrowdIndexという指標に基づいて各画像の混雑度を測ることで、様々な混雑度の画像がバランスよく含まれるように構成した。
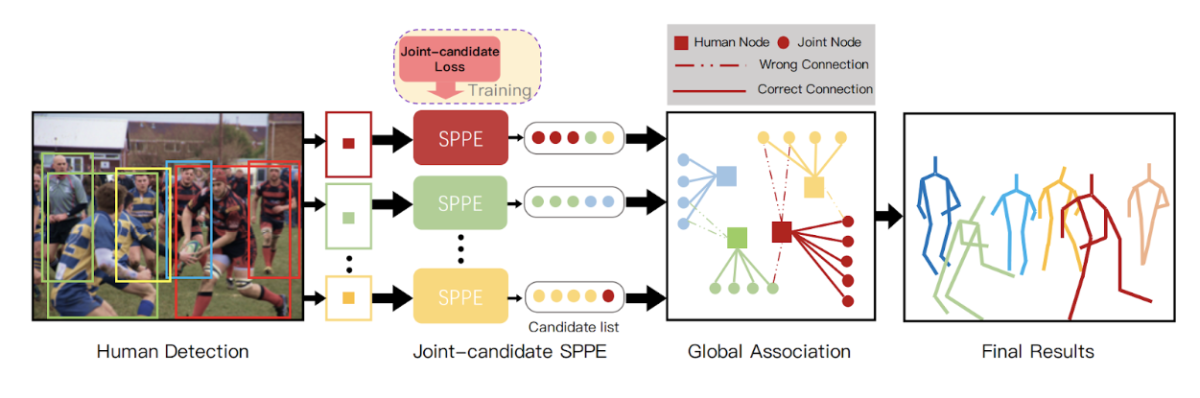
図A1:提案手法。それぞれのbox内に存在する全器官点を単一人物姿勢推定ネットワークで推定、Global Associationにて全boxの器官点を各人物に割り当てて最終出力とする。
結果
Crowd Indexに対する各デファクト手法の精度を見ると (図A2左)、Crowd Indexの大小でmAPが20ポイントも変化することがわかる。一方、各データセットにおけるCrowdIndexの分布 (図A2 中央・右)によると、新たに作成したCrowdPoseは様々な混雑度の画像をまんべんなく含んでいる。
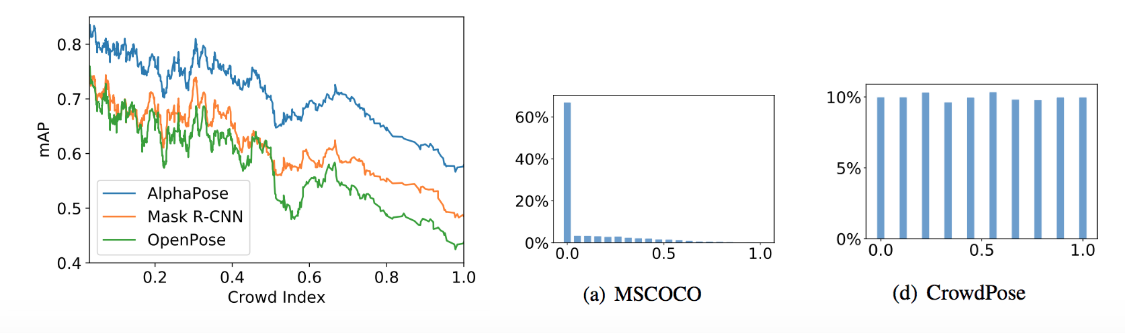
図A2:Crowd Indexとランドマーク精度の関係(左)、MSCOCOとCrowdPoseデータセットにおけるCrowd Indexの分布 (中央、右)
CrowdPoseデータセットを用いた、提案モデルのベンチマーク結果は図A3のようになった。OpenPose、Mask R-CNN、AlphaPose、Xiaoらの手法 (*3) を上回っている。
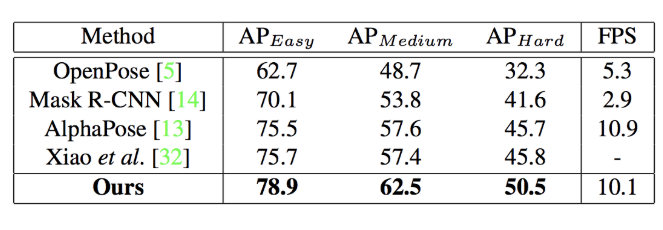
図A3: CrowdPoseデータセットによるベンチマーク
MSCOCOデータセットを用いたベンチマークにおいても高い精度となった。やはりMask R-CNN、AlphaPose、Xiaoらの手法を上回っている。
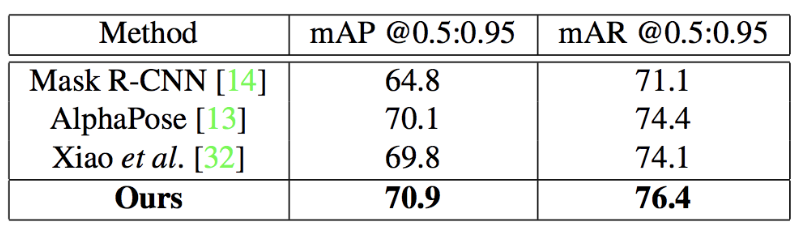
図A4:MSCOCOデータセットによるベンチマーク
リンク
論文: https://arxiv.org/abs/1812.00324
*1 YOLOv3: 2018年に発表された、リアルタイム動作可能な物体検出モデル。
*2 AlphaPose: regional multi-person pose estimation (RMPE) という手法の別称。
https://arxiv.org/abs/1612.00137
*3 Xiao et al., の手法は当時SOTAであったが、オープンソース化されていなかったため著者らが再現実装したと思われる。フェアに比較するため人物領域検出はYOLOv3を用いた。ちなみに2018年8月にPyTorch実装がオープンソース化されている。
https://github.com/Microsoft/human-pose-estimation.pytorch
Deep High-Resolution Representation Learning for Human Pose Estimation
要約
ポーズ推定ネットワークを強化、複数スケールのinteractionを密にしてフュージョンすることで精度を向上した
提案手法
single-person pose estimator (SPPE) としては、ダウンサンプリングネットワークとアップサンプリングネットワークからなるHourglass network(U-Netもその一種である)が主流であるが、 本論文で採用するHigh-Resolution Net (HRNet) では、図B1のように、1xの解像度 (HR) を持ったfeature mapが常に伝播し他のスケールと相互作用する設計となっている。これにより器官点のlocalization精度が向上する。
入力画像はstride=2の2層のconv層を経てHRNetに入力される。すなわちHRNet入力時のfeature mapは入力画像の1/4スケールとなっている。HRNetの1x, 2x, 4x, 8xの4スケールは入力画像に対してはそれぞれ4x, 8x, 16x, 32xのスケールに相当し、チャンネル幅はそれぞれ32, 64, 128, 256である(HRNet-W32ネットワーク)。異なるスケールのfeature mapはアップサンプリング (strided 3x3 convolution) またはダウンサンプリング (1x1 convolution + nearest neighbor) されて加算される。ネットワークの最終段は1x, 2x, 4x, 8xの4スケールが出力されるが、このうち最も精度の高い1xの出力のみが用いられる。損失関数はground truthのキーポイントヒートマップに対するmean square errorである。
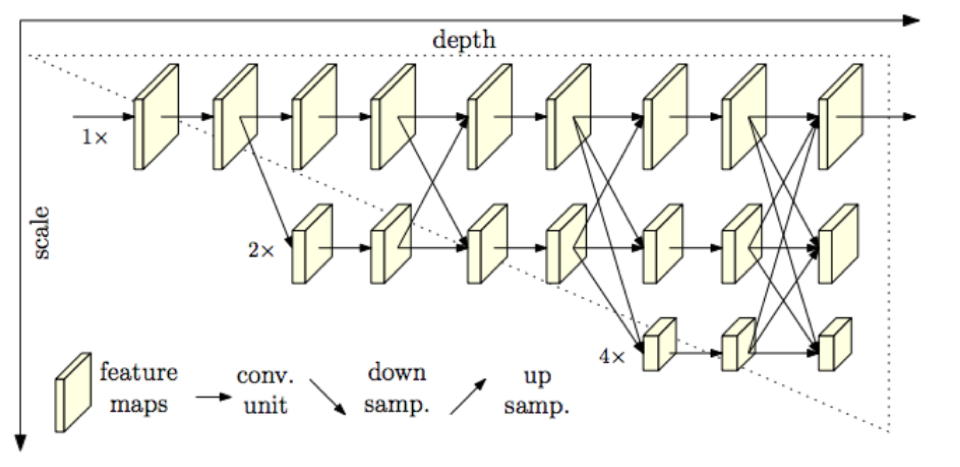
図B1:提案手法HRNetのネットワーク図。縦軸が入力スケールを基準にしたfeature mapのスケール、横軸がCNNのdepthを表す。入力スケールは入力画像の1/4である。
結果
著者らの前作であるSimple Baselines for Human Pose Estimation and Tracking (ECCV Posetrack challenge 2018で優勝)を大きく上回り、Average Precision vs 演算量のトレードオフを改善した(図B2)。
図B3に、HRNet及び著者らの前作Simple Baseline(ResNet50 + upsampling)の演算量内訳を示す。トータルの演算量は7GFLOPs (HRNet) 、9GFLOPs(Simple Baseline) と低減されている。その主な原因はSimple Baselineにて演算量の6割を占めていたupsamplingレイヤがなくなり、HRNetに統合されたことによる。図B4はMPII及びCOCOデータセットによるテスト結果である。
図B5に、ポーズ検出手法のCOCO test-devにおける比較結果を示す。
OpenPose 61.8%、Mask R-CNN 63.1%、Cascaded Pyramid Network (CPN) 73.0%、Simple Baseline 73.7%、また上述CrowdPose 70.9%に対して、HRNetは75.5%とさらに高精度となっている。PoseTrackデータセットにおいても、精度面でSOTA手法となっている。
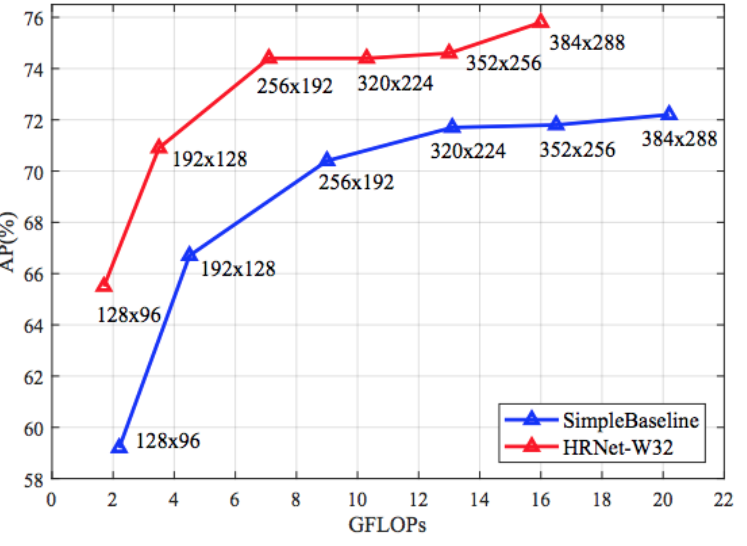
図B2:HRNetと、著者らの前作であるSimpleBaseline (ResNet50) のAP(ランドマーク精度) vs GFLOPs(演算量)トレードオフ比較。
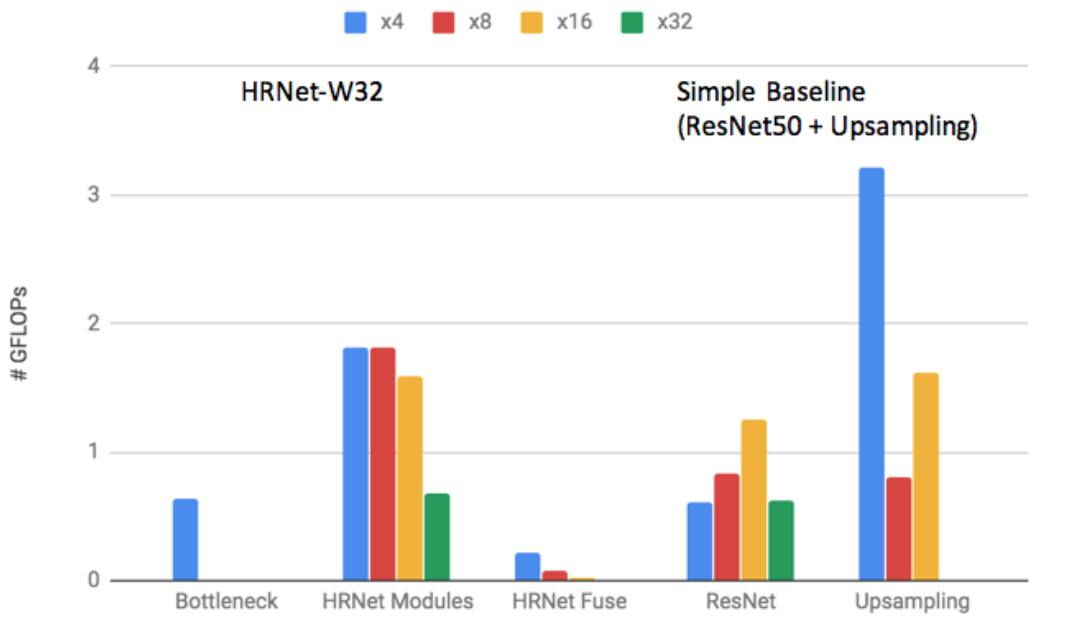
図B3: HRNetと、著者らの前作であるSimpleBaseline (ResNet50) のネットワーク部位別計算量

図B4:MPII (上段)およびCOCO (下段)でのテスト結果
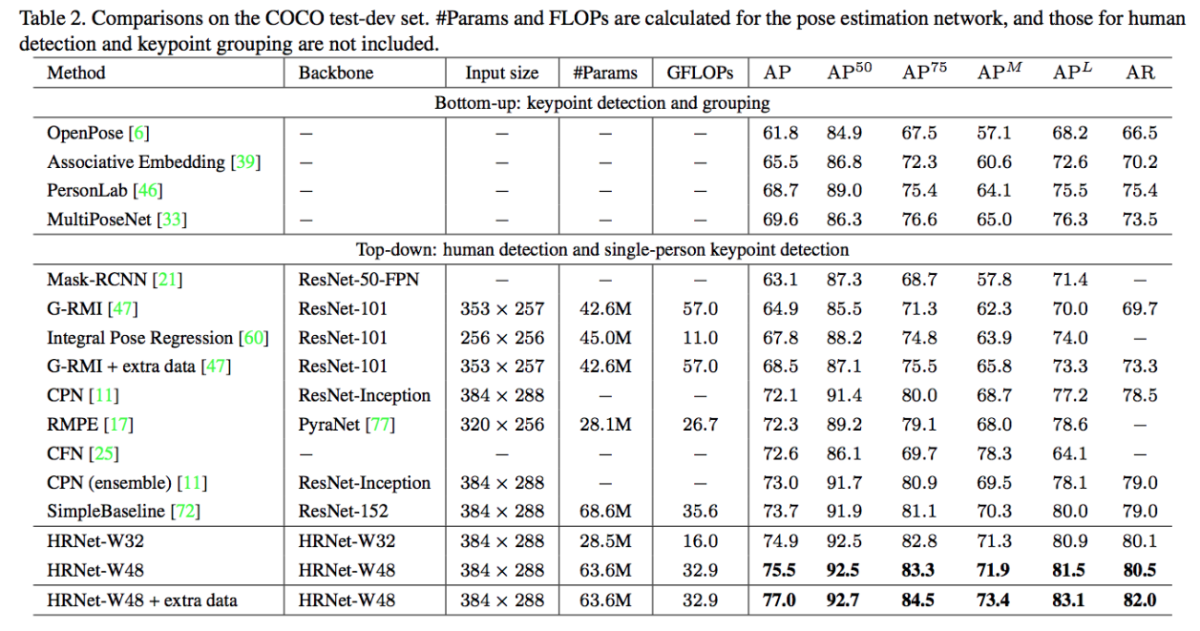
図B5: COCO test-devでの性能比較結果
リンク
論文:
https://arxiv.org/abs/1902.09212
PyTorch実装:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Monocular Total Capture: Posing Face, Body, and Hands in the Wild (CVPR2019 Oral)
要約
単眼2D画像のみから顔、体、手を含む全身の3Dモーションを推定するMarkerless Motion Capture手法。

図C1:Monocular Total Captureの実行結果。単眼カメラ画像から3Dのモーションキャプチャ情報を推定する。
提案手法

図C2:提案手法の処理の流れ。CNN部、メッシュフィッティング部、メッシュ追跡部からなる 2次元画像シーケンスを入力して、各フレームの3D人体モデルのモーションキャプチャー情報を出力する。 身体モデルは著者らによる前作であるTotal Capture で提案された3D Deformation Modelを用いる。
提案手法は図C2に示すように、3ステージに分けられる。
- CNN部:i フレーム目の画像をCNNに入力し、 器官点の位置 (Joint Confidence Maps) と、各器官点間の3Dベクトル (Part Orientation Fields) が得られる。
- メッシュフィッティング部:可変人体モデルを上記出力S、Lで調整することで人体のモーション推定をする。このステージで一フレームの人物3Dメッシュ推定が可能となる。
- メッシュ追跡部:i - 1フレーム目の画像とパラメータを入力することで、モデルのパラメータを調整、複数フレームでのtime consistencyを向上する。
Part Orientation Fields Lは図C3のように、器官点間の3Dベクトルをヒートマップとして推定する。OpenPoseに用いられるPart Affinity Fieldと類似している。
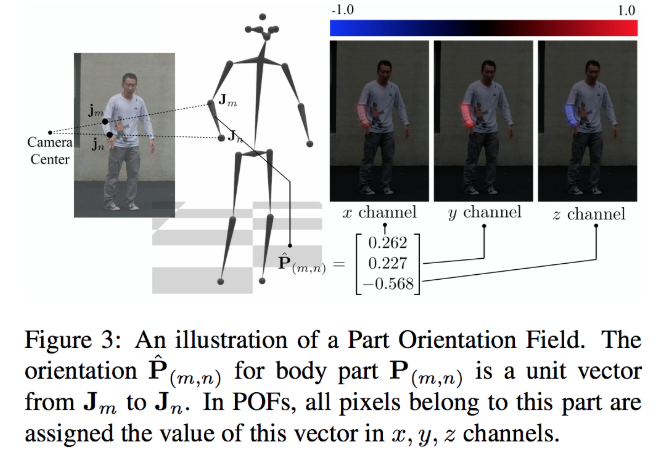
図C3:Part Orientation Fieldの説明図。器官点間の3Dベクトルがヒートマップとして推定される。 CMU Panoptic Studio を用いて 834K の身体画像と 111K の手画像を3D姿勢アノテーション付きで取得し、新データセットを構成した(未公開)。
結果
身体部位のモーション推定データセットHuman3.6M (in-the-wild) 、及び手姿勢データセットSTB datasetでSOTAとなった。

図C4:Human3.6Mでのベンチマーク結果。
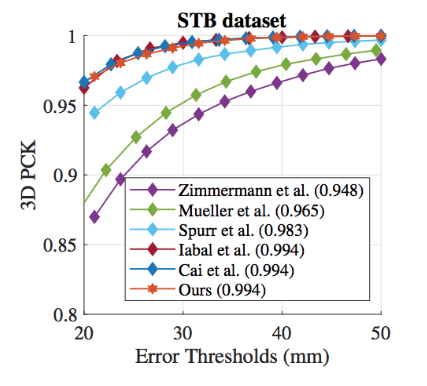
図C5:STBデータセットでの手姿勢推定ベンチマーク結果。
リンク
論文:
https://arxiv.org/abs/1812.01598
動画:
https://www.youtube.com/watch?v=rZn15BRf77E
Parsing R-CNN for Instance-Level Human Analysis
要約
人物インスタンス認識に関するタスクであるHuman Parsing及びDensePose Estimation において高精度なR-CNN手法を提案する。
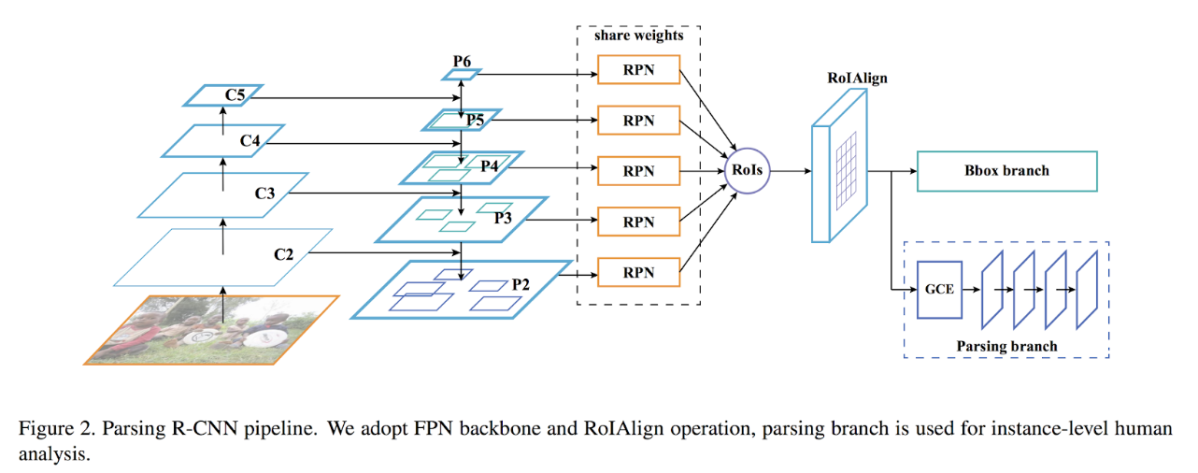
図D1:Parsing R-CNNのパイプライン全体図。Feature Pyramid Netwokをバックボーンとし、ROIAlignでクロップしたROIごとにBbox branchとParsing branchを適用する。
提案手法
- 特徴抽出部: proposals separation sampling (PSS) という手法を提案する。Feature Pyramid Network (FPN) とほぼ同じ構造だが、Region Proposal Network (RPN) によって得られた注目領域に対し、最も解像度の高いP2スケールのfeature mapをクロップすることが特徴である。
- Bbox Branch : クロップした領域に対し、bounding boxの回帰を行う。
- Parsing branch:新提案のGeometric and Context Encoding (GCE) モジュールを適用、セグメンテーション(Human parsing)やdense pose推定を行う。GCEの前半はAtrous spatial pyramid pooling (ASPP) (*1) でマルチスケールの情報を獲得し、後半はNon-local Neural Network(*2) を適用、それぞれ精度向上に寄与している。GCEの前後にconv層を挿入する実験を行なったが、前に入れたときの効果が薄かったため、GCEの後に4層のconvを入れるアーキテクチャとした (図D1)。
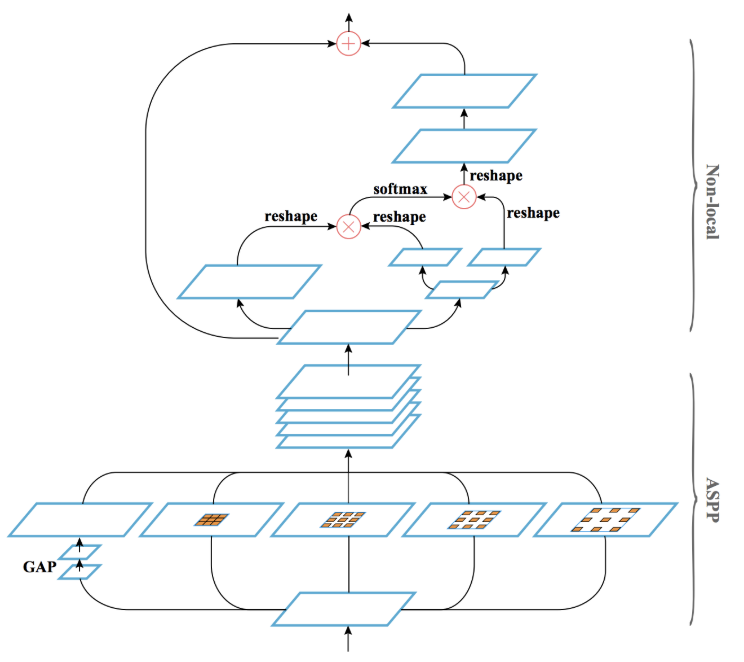
図D2: Parsing branch(図D1右下部)を構成するGeometric and Context Encodingモジュール。
結果
CIHP (Crowd Instance-level Human Parsing) 、MHP v2.0 (MultiHuman Parsing) と DensePose-COCO データセットでSOTAとなった(図D3、D4)。

図D3:(a) 入力画像 (b) DensePoseタスクの推定結果 (c) 入力画像 (d) Human Parsing結果
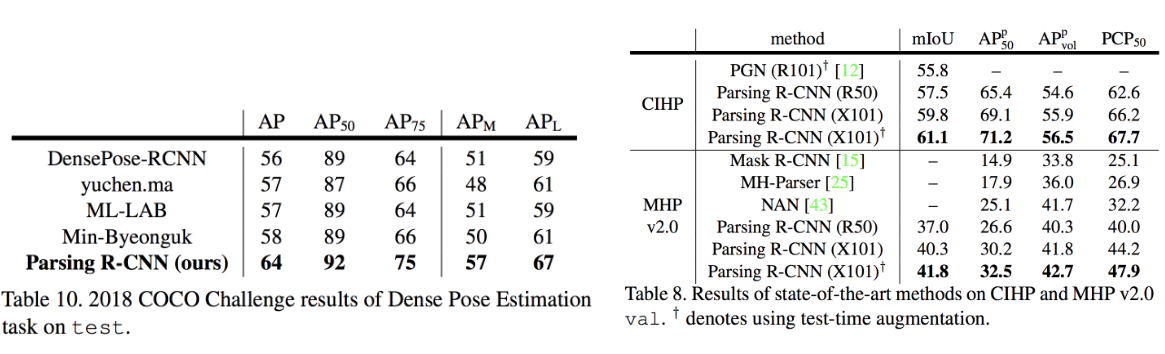
図D4: (左)DensePose タスクの評価結果、(右)CIHPデータセット, MHPデータセットにおけるHuman Parsingタスクの評価結果
リンク
論文: https://arxiv.org/abs/1811.12596
*1 Atrous spatial pyramid poolingはsemantic segmentationタスクにおいて有効なモジュールで、dilation rateの異なるdilated convolutionを並列に用いることでreceptive fieldを広げる効果がある。論文は
https://arxiv.org/abs/1802.02611
*2 Non-local Neural Networkはfeature map上で空間的に離れた位置にある、類似したfeature を統合することでfeature mapの質を向上する手法である。論文は
https://arxiv.org/abs/1711.07971
3D Hand Shape and Pose Estimation from a Single RGB Image (CVPR2019 Oral)
要約
RGB 画像から手の 3D 姿勢と 3D メッシュを同時推定する手法を提案、GPU で 50 FPS で動作する(図E1)。
提案手法
この論文では,Graph CNNと合成画像を活用し、RGB 画像から手の 3Dメッシュと3D姿勢を推定する手法を提案している。3Dメッシュデータは自然にグラフ構造を持つため, Graph CNNが有効である。 実画像に対し 3D メッシュのアノテーションをつけることは容易でないため合成画像を活用し学習する。具体的には、3D メッシュありの合成画像で教師あり学習をした後、RGBDの実画像データを用いて、弱教師ありのfine-tuningを行う。3D姿勢は3Dメッシュから線形なGraph CNNで回帰する(図E2)。
推定パイプライン(図E2, E3)
- stacked hourglass networkで2D heat map推定
- heat map と画像特徴を合わせたものをResNetで特徴ベクトルに変換
- 変換した特徴ベクトルからGraph CNNでメッシュ推定
- メッシュからLinear Graph CNNで3Dキーポイント推定
合成画像での学習時のloss:
- heat-map loss: 2D 画像でのキーポイント推定のloss
- 3D pose loss: 3D キーポイント推定のL2 loss
- mesh loss: これは更に分解されて、頂点、辺、法線、滑らかさに関する 4 つの loss からなる
実画像に対する fine-tune時のloss:
- heat-map loss: 合成画像の場合と同じ
- depth map loss: メッシュを differentiable rendererで深度画像にレンダリングしたものと GT との smooth L1 loss
- pseudo-ground truth loss: GT 画像、GT heat mapからpseudo-GTメッシュを作り、そこからエッジの長さ、滑らかさが離れ過ぎないように loss をかける。Depth map lossのみだと見えている部分以外がおかしくなるため
結果
RGB からの 3D メッシュの推定は既存手法には無いが素朴なベースラインを上回る性能。3D 姿勢の推定では既存データセットで SOTA (図E4)。STBデータセット(図中央)では、上述のMonocular Total Captureよりも高いAUCとなっている。GTX 1080 で 50 FPS動作する。

図E1: 提案手法による推論結果。2D/3Dのキーポイントだけでなく、3Dメッシュも生成している。(上) 合成画像データセットでの結果、(中) 実画像データセットでの結果、(下) STBデータセットでの結果。
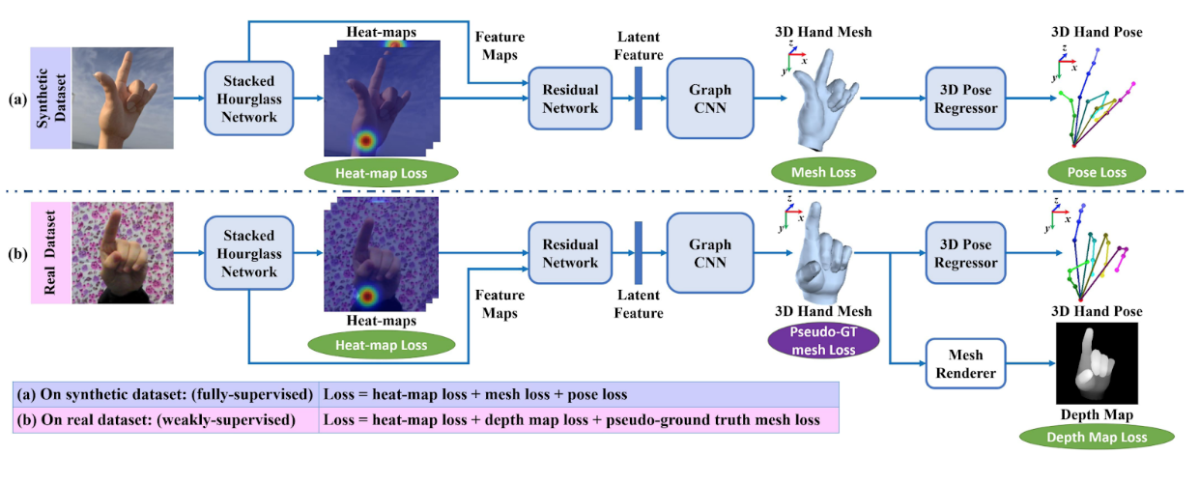
図E2: 提案手法の学習方法の概要。(a) 合成画像データセットによる学習、(b) 実画像データセットによるfine-tuning。
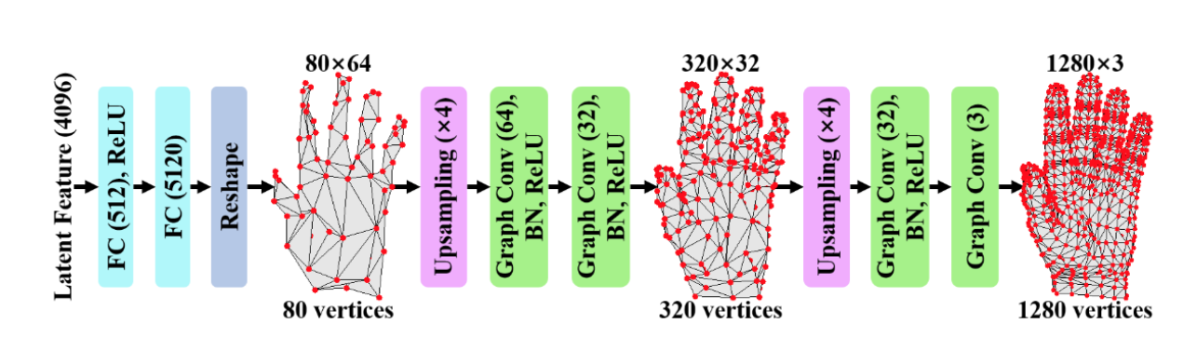
図E3: 手の3Dメッシュを生成するGraph CNNのアーキテクチャ。
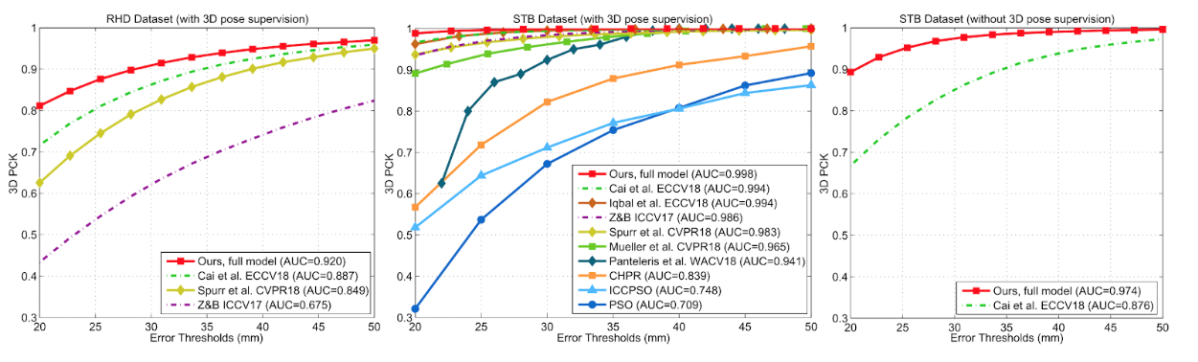
図E4: 既存手法との比較。(左)RHDデータセットでの結果、(中)STBデータセットでの結果、(右)STBデータセットで3D姿勢なしで深度画像を使って弱教師あり学習した場合の結果。
リンク
論文: https://arxiv.org/abs/1903.00812
おわりに
今回はHuman Recognitionと題して、RGB画像からの人物・手の姿勢推定やモーションキャプチャ情報の推定、セグメンテーションに関する論文を紹介しました。
人物のポーズ認識はさらに高精度化を遂げ、人物が重なり合っている画像でもそれぞれのキーポイントを検出することが可能となってきています。身体や手の3Dポーズ推定やメッシュ推定も、単眼のRGB画像からできるようになってきました。
人の認識技術は今後も重要分野として進展し、さまざまな新しい応用が生まれてくると考えられます。DeNA CVチームでは引き続き調査を継続し、最新のコンピュータビジョン技術を価値あるサービスに繋げていきます。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。