





この記事は DeNA Advent Calendar 2018 の24記事目です。
こんにちは、セキュリティ部セキュリティ技術グループ ツール開発チームの小竹 泰一(aka tkmru )です。 脆弱性診断業務の傍ら、ツール開発チームでは、パッチ管理ツールやチート対策、脆弱性診断のためのツール開発を行っています。 この記事では開発中のLLVMを用いたチート対策ツールの紹介をしたいと思います。
はじめに
本題に入るまえに、チートをされるとどのような問題があるのか、チートの方法やチート対策技術にはどのようなものがあるのかということを軽く説明しようと思います。
チートによるリスク
スマートフォンのゲームアプリのチートでよくあるものとしては、 「スタミナが減らないようにするもの」や、 「ステータスを不正に上昇させバトルで勝利するもの」、 「不正に課金アイテムを取得するもの」などがあります。
もし、このようなチートが横行してしまうと、適切に利用しているユーザの快適なプレイが阻害されてしまうかもしれません。 また、不正に課金を回避したり、ステータスをアップさせているユーザの存在は他のユーザの納得感を得られないでしょう。 チーターの存在はゲームバランスにも影響し、ゲームからユーザーが離れる一因となります。 ゲームアプリの脆弱性診断では、ゲームに対して実際に攻撃を行うことで、このようなチートからゲームを守ることができるかを確認しています。
チート対策技術とは
上で述べたように、チート対策はゲームの魅力を守るために重要です。 とくに、近年のゲームアプリはUX向上の為クライアント側の計算により多くのゲームロジック(スコア・ダメージの計算、勝敗判定など)を寄せています。 そのため、リバースエンジニアリングを伴う攻撃への耐性を上げることが重要なチート対策となっています。
ゲームアプリに限った話ではなく一般的に言えることですが、リバースエンジニアリングの手法は、アプリケーションを実際に動作させメモリや通信内容を解析する動的解析と、 ディスアセンブラやデコンパイラにかけた結果を解析する静的解析の2つに分類されます。 ARMアセンブリのコードを読む必要のある静的解析は動的解析に比べ、難易度が高いですが、 用いられている暗号方式などの詳細な解析結果を得るには行う必要があります。
ゲームアプリのチート対策では、この2つに対して対策する必要があります。 ここではひとつひとつを詳細に説明することはしませんが、チート対策技術には以下のようなものがあります。
- 通信の暗号化
- Root化端末、JailBreak端末の検知
- VMの検知
- デバッガ検知
- メモリ上のデータの暗号化
- パッキング
- コード改ざんの検知
- 難読化
- … etc
紹介するLLVMを用いたチート対策ツールでは、コードの処理の流れを追いにくくする難読化と、 パッチを当てられたことを検知するコード改ざん検知を担っています。 コードの改ざんを検知した後にやることとしては、アプリを強制的に終了させることや、ログをサーバーに送信することが考えられます。
LLVMとコンパイラ
LLVM は、コンパイラ開発のためのオープンソースの基盤ソフトウェアです。 主な特徴として、コンパイルに必要な機能がモジュール化され,各機能を統合するドライバで構成されており、拡張性、移植性に優れていることが挙げられます。
コンパイラの設計手法の一つにフロントエンド、optimizer、バックエンドの3つの構成要素に分割して設計するThree-Phase Designがあります。 LLVMを用いてThree-Phase Designを採用してコンパイラを設計すると、 内部構造は以下の画像( The Architecture of Open Source Applications: LLVM より引用)のようになります。
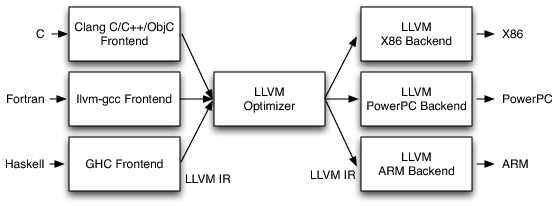
フロントエンドがプログラムのソースコードをLLVM IRという中間表現に変換し、 LLVM optimizerがLLVM IRのコードに対して最適化をかけます。 そして最後にLLVMバックエンドがLLVM IRのコードからターゲットのアーキテクチャのアセンブリコードを生成し、 実行可能ファイルを生成する流れになっています。
コンパイラ開発にLLVMを利用すると、中間表現をLLVM IRに統一することができ、 異なるアーキテクチャ向け、異なる言語向けのコンパイルであっても最適化部分を共通化できます。 しかも、その最適化機構は Pass としてLLVMが提供してくれています。 また、バックエンドを置き換えるだけで異なるアーキテクチャに対応できたり、フロントエンドを置き換えるだけで異なるプログラミング言語に対応できたりもします。 このようにLLVMを利用することで、1からコンパイラを作成するより効率よくコンパイラを作成することができます。
LLVM IR
LLVM IRについてもう少しくわしく見ていきましょう。 LLVM内部で用いられる中間表現であるLLVM IRは、 アセンブリ言語に似た表現で、表現力や拡張性、軽量であることを追求して作られています。 基本的な命令による操作の組み合わせで、 様々な高級言語に対応した簡潔な表現が可能になっています。 また、LLVM IRのレジスタは数に制限が無く、値の代入が一箇所でしか行えないSSA(Static Single Assignment)形式になっており、 これを用いて柔軟に変数を表現することができます。 LLVM IRには様々な種類の型が存在し、レジスタに型が対応しており、 細分化された型は高度な最適化を可能にします。 例えば、32bit整数型を表すi32型や、 128bit浮動小数点数型を表すfp128型などがあります。 これらの基本となる型と組み合わせて、構造体、配列、ベクトルといった 派生型を構成することができます。
実際にLLVM IRのコードを見てみましょう。 以下のような西暦を出力するだけのコードをLLVM IRに変換します。もうそろそろ2019年ですね。
#include <stdio.h>
int main(){
int year = 2018;
printf("%d", year+1);
return 0;
}
clangに-S、-emit-llvmの2つのオプションを指定するとLLVM IRコードが出力されます。
$ clang new-year.c -S -emit-llvm
$ cat new-year.ll
; ModuleID = 'new-year.c'
source_filename = "new-year.c"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.13.0"
@.str = private unnamed_addr constant [3 x i8] c"%d\00", align 1
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 2018, i32* %2, align 4
%3 = load i32, i32* %2, align 4
%4 = add nsw i32 %3, 1
%5 = call i32 (i8*, …) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str, i32 0, i32 0), i32 %4)
ret i32 0
}
declare i32 @printf(i8*, …) #1
attributes #0 = { noinline nounwind optnone ssp uwtable “correctly-rounded-divide-sqrt-fp-math”=“false” “disable-tail-calls”=“false” “less-precise-fpmad”=“false” “no-frame-pointer-elim”=“true” “no-frame-pointer-elim-non-leaf” “no-infs-fp-math”=“false” “no-jump-tables”=“false” “no-nans-fp-math”=“false” “no-signed-zeros-fp-math”=“false” “no-trapping-math”=“false” “stack-protector-buffer-size”=“8” “target-cpu”=“penryn” “target-features”="+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" “unsafe-fp-math”=“false” “use-soft-float”=“false” }
attributes #1 = { “correctly-rounded-divide-sqrt-fp-math”=“false” “disable-tail-calls”=“false” “less-precise-fpmad”=“false” “no-frame-pointer-elim”=“true” “no-frame-pointer-elim-non-leaf” “no-infs-fp-math”=“false” “no-nans-fp-math”=“false” “no-signed-zeros-fp-math”=“false” “no-trapping-math”=“false” “stack-protector-buffer-size”=“8” “target-cpu”=“penryn” “target-features”="+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" “unsafe-fp-math”=“false” “use-soft-float”=“false” }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !“wchar_size”, i32 4}
!1 = !{i32 7, !“PIC Level”, i32 2}
!2 = !{!“Apple LLVM version 9.1.0 (clang-902.0.39.2)”}
レジスタが%数値で表されているのが特徴的ですね。
アセンブリとは違い、アドレスの概念がないので操作しやすそうなのが分かると思います。
Three-Phase Designについて説明をした際、異なるアーキテクチャに対して最適化部分を共通化できると述べましたが、それ以外にも LLVM IRを用いることで対象のソースや機械語に手を加えることなく、最適化を行うことができるというメリットがあります。
LLVMをなぜ使うのか
LLVM IRを最適化に使うと便利だということを述べましたが、これは難読化やコード改ざん検知機能を実装するのにも同じことが言え、 LLVM IRを用いることで対象のソースや機械語に手を加えることなく、出力されるバイナリに難読化やコード改ざん検知機能を施すことができます。 また、現在スマートフォンで用いられているCPUはARMが主流ですが、異なるアーキテクチャのCPUを用いたスマートフォンが出てきたときの対応も容易になります。 LLVMを使って難読化に行うこと自体は、新しい手法ではなく、OSSの実装として obfuscator-llvm/obfuscator が知られています。
Unityで作られたゲームアプリのコードは IL2CPP を利用してC++のコードに変換することができます。 開発中のチート対策ツールでは、 この出力されたC++のコードをLLVM IRに変換し、 難読化やコード改ざん検知をいれ、 最終的にバイナリにするという方式をとっています。
難読化例
プロトタイプのチート対策ツールを使用するとCFG(Control Flow Graph)を以下のように変化させることができます。 CFGはIDA Proを使って生成しました。 これによって処理の流れが追いにくくなります。
難読化前のCFG

難読化後のCFG

今のところ、まだIDAのGraph viewでCFGを表示することができますが、最終的にはAnti-Disassemblyを施してCFGを表示できないようにする予定です。
おわりに
開発中のチート対策ツールの技術的な背景を紹介しました。 マルウェアがアンチデバッグに使っている手法などを検証しながら、 低レイヤーでの開発ができる、 このツールの開発はとてもおもしろいと思っていて、 商用ツールに負けないようなツールにしていきたいと思っています。 チート対策やLLVMを使ったツール開発の面白さが少しでも伝われば幸いです。
宣伝
DeNA TechCon 2019 を2019年2月6日(水)に開催します! ぜひご登録下さい! セキュリティに関する話 もあります!!

また、弊社についての技術情報は @DeNAxTech より配信しています。ぜひフォローをお願いします!!




{kind=link}
最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。