





はじめに
AIシステム部・AI研究開発グループの益子です。 現在はオートモーティブ事業において、AI研究開発エンジニアとして働いています。
先月20日、DeNA社内において、アマゾン ウェブ サービス ジャパン(AWS)様より「Amazon SageMaker」ハンズオンを実施していただきましたので、その模様をレポートさせていただきます。
DeNAでは、すでに数多くのサービスでAWSを活用しています。私の所属するAIシステム部もその例外ではなく、機械学習のモデル開発に幅広く利用しています。
昨年のAWS re:Invent 2017において「Amazon SageMaker」が発表されましたが、発表の後さっそく社内でも利用したいという声が上がり、AWS様より社内エンジニア向けハンズオンを実施していただけることになりました。
Amazon SageMakerとは
Amazon SageMakerとは
- AWSインスタンス上にJupyter Notebookを構築
- Notebook上での機械学習モデル実装
- AWSのインフラを利用した、分散学習
- 学習したモデルを組み込んだ予測APIの自動生成
まで一貫して行える、フルマネージドサービスです。
https://aws.amazon.com/jp/blogs/news/amazon-sagemaker/
Jupyter Notebookといえば、すでにデータ分析/機械学習アルゴリズム開発においてデファクトとなりつつあるツールですが、それがコンソールからポチポチするだけで、簡単に構築できるのはかなり大きなメリットとなります。
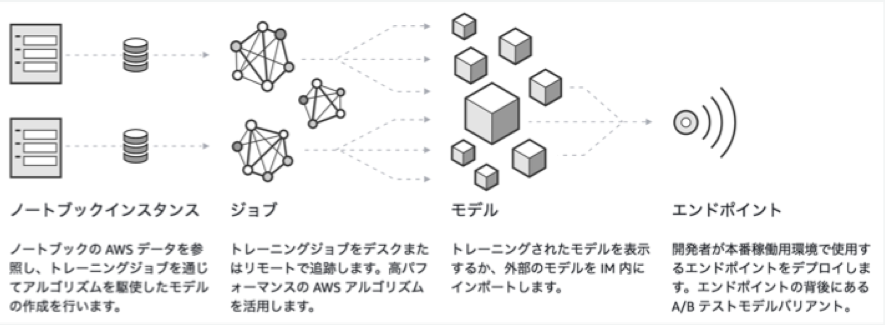
また、これまで機械学習サービスを開発する場合には
- 学習環境構築とデータ整備 (インフラエンジニア)
- 機械学習モデル実装(機械学習エンジニア)
- 学習済みモデルをサービス内にデプロイ(サービス開発エンジニア)
の手順が必要であり、案件によっては複数のエンジニアが関わる必要がありました。
SageMakerにより1.と3.の手順がほぼ自動化されるため、機械学習エンジニアはモデル実装に集中でき、また単独でサービス展開まで行うことも可能になります。
ハンズオンの流れ

当日は、AWSより志村誠さんを講師に迎え、主に機械学習アルゴリズムのサービス適用という話題を中心に講演していただきました。
前半はスライドを用いてSageMakerの概要の説明、後半は実際に弊社環境内にJupyter Notebookを立ち上げて、ハンズオンという形式になっています。
ハンズオン参加者の内訳
DeNAからはエンジニアを中心に50名超参加しました。
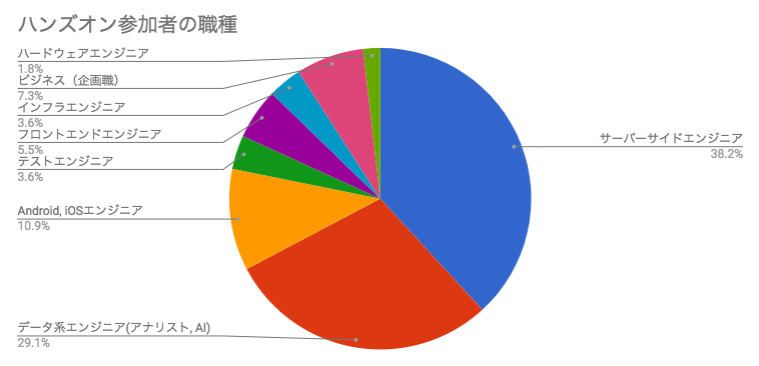
参加者の内訳を見ると、幅広い分野のエンジニアが参加しています。また今回エンジニア向けとして開催したのですが、ビジネスメンバーからも参加があり、機械学習への関心が非常に高いことが伺えます。
それでは、以下当日のハンズオンの流れに沿って、詳細をレポートしていきます。
前半: 講義
前半は講義形式をとり、SageMakerについて解説していただきました。

SageMakerを利用して機械学習を行う場合、主に3つの選択肢があります。
- ① AWSが提供するアルゴリズムを利用
- ② AWSがサポートするフレームワークを利用
- ③ それ以外のアルゴリズム・フレームワークを利用
もっともお手軽なものが①で、すでにある程度の機械学習アルゴリズムはプリセットとして用意されています(後述)。
②は①に含まれないアルゴリズム、例えばディープラーニングモデルを独自に実装したい場合に利用することになります。対応しているフレームワークは限られていますが、分散学習もサポートされるので、柔軟性もありつつ、クラウドのメリットを享受できます。
もっとも柔軟性があるのは③の方法ですが、こちらは学習用のDockerコンテナを自前で用意する必要があり、一手間必要です。その代わり、①、②で提供されていないアルゴリズム・フレームワークが利用可能となります。 DeNAではchainerで開発しているチームも多く、その場合は③の方法になります。今後も①〜③の方法を適材適所で使い分けていくことになると思います。
①のAWS提供アルゴリズムですが、すでに一般的な回帰・分類問題などがカバーできるように用意されているようです。

今回のハンズオンでも、①Amazon提供のアルゴリズムを利用した線形回帰問題のケースを実装していきました。
後半: ハンズオン

ここからは、参加者全員分のJupyter Notebookインスタンスを立ち上げ、実際にSageMakerによる機械学習をいくつか試していきます。
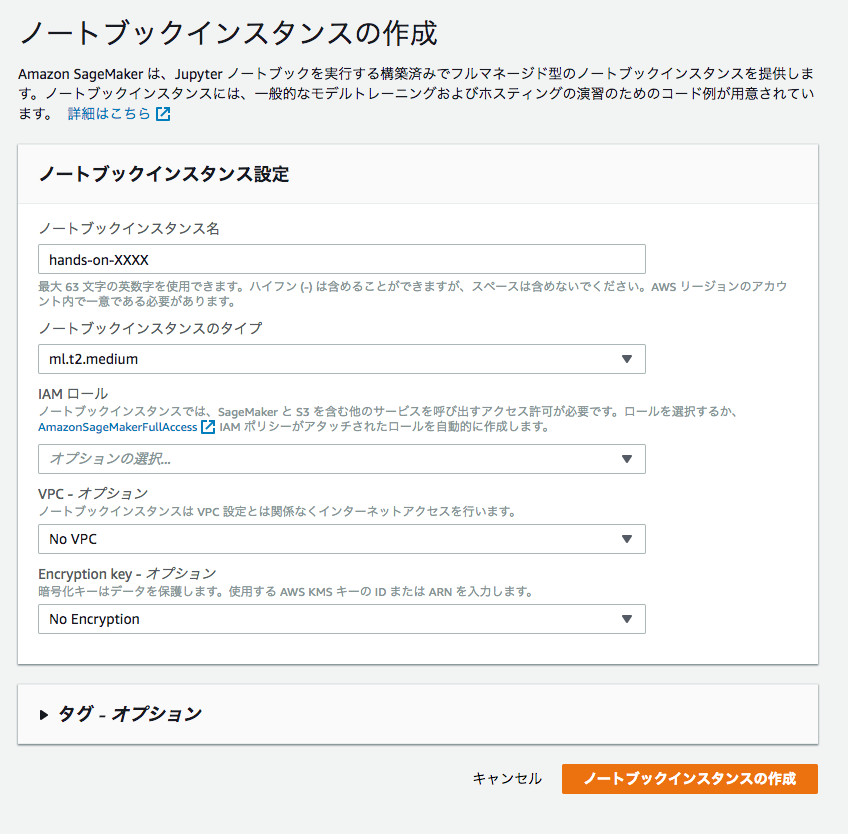
Notebook インスタンスの作成
Notebookに利用するインスタンスタイプなどを設定するだけで、あっという間にJupyter Notebookが立ち上がりました。
AWS提供アルゴリズムによる線形回帰 - 学習
サンプルとして、まずはAWS提供アルゴリズムの線形回帰モデルを試しました。
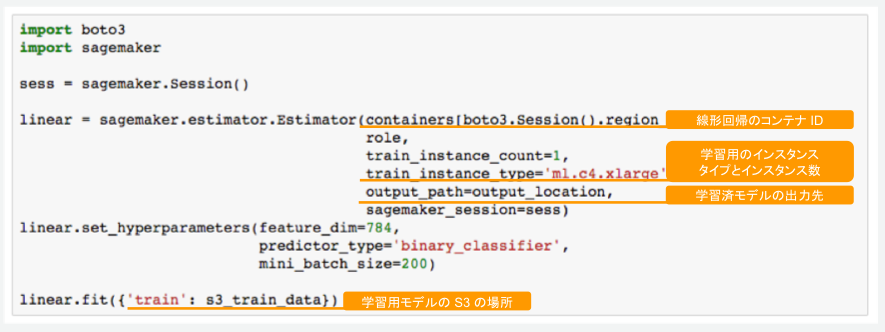
データロードの部分は省きますが、AWS提供のアルゴリズムを利用した場合、上記コードだけでモデル学習を実行してくれます。学習用の関数であるlinear_estimator.fitを実行すると、Notebook インスタンスとは別に学習用のコンテナが立ち上がり、ジョブを実行してくれます。
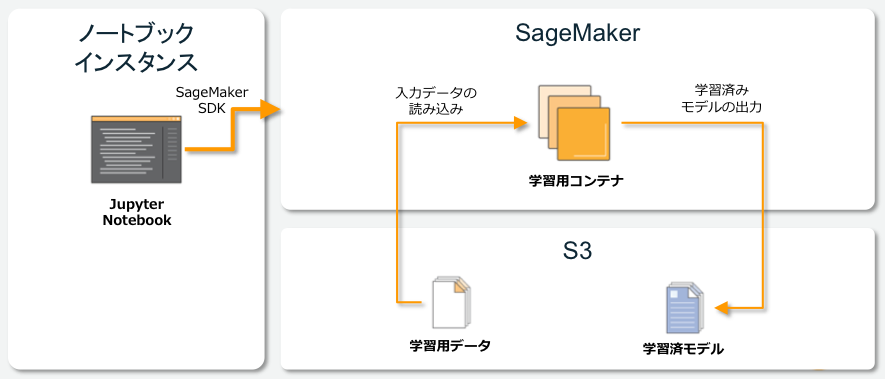
内部の挙動としては、SageMakerがS3から事前に配置した学習データを読み込み、コンテナ上で学習、学習した結果のモデルを再度S3に書き戻しておいてくれる、という仕組みになります。
S3に出力される学習済みモデルファイルですが、AWS提供アルゴリズムの場合はSageMaker専用になっているためエンドポイント経由での推論が前提となります。一方でDLフレームワークで独自実装した場合や、学習用コンテナを用意して学習したモデル(手法②、③)に関しては、S3から直接モデルファイルを取得して推論アプリケーションに組み込むことができるそうです。
AWS提供アルゴリズムによる線形回帰 - デプロイと推論

学習が終われば、上記のようにdeployを実行するだけで推論エンドポイントが作成されます。
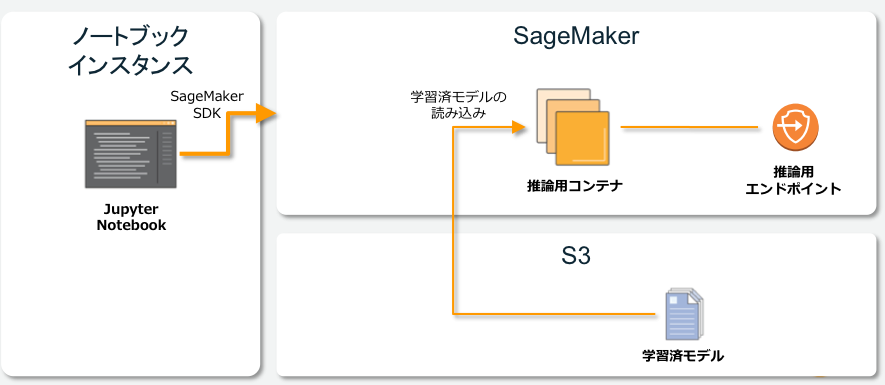
作成したエンドポイントに対して、入力データを投げると、推論結果が返ってきます。ハンズオンではHTTPリクエストをする代わりに、ノートブック上から直接エンドポイントを実行する方法をとりました。

今回割愛させていただきますが、ハンズオンではその他、tensorflowによるirisデータセットの分類問題にも取り組みました。
DeepAR による時系列予測
講演の中では、 DeepAR 使った時系列予測タスクも紹介されましたので、手元でも試してみました。
データセットとして予め波形データを作成し、これを学習させます。
ここでは実行コードは省きますが、全体の処理の流れは線形回帰で試したものと同様です。
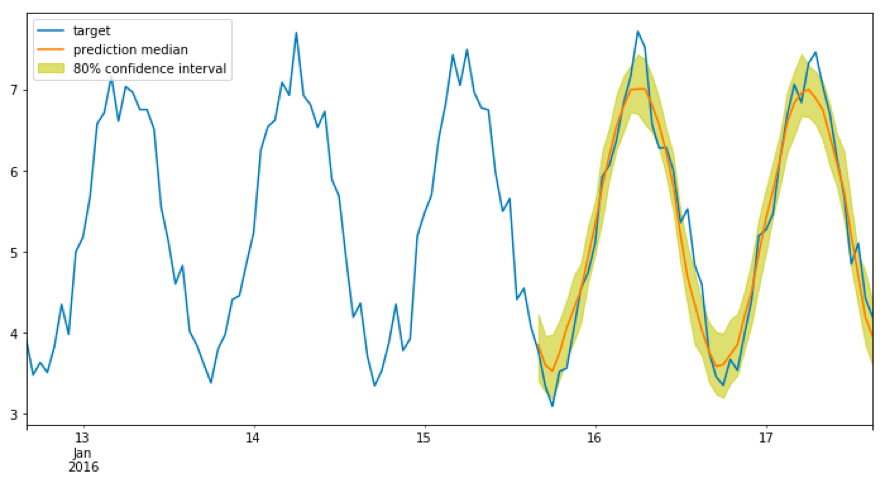
推論結果として、80%信頼区間と予測中央値を得ることができました。 トレンドはうまく捉えられているようですが、ピーク部分にずれがあります。ここはさらなるチューニングで改善できるかもしれません。
DeepARは元々、Amazon.com内における予測タスクに利用していたものだそうです。 AWS提供アルゴリズムのため、特別なセットアップをする必要なく、時系列予測問題に適用することができます。 時系列予測モデルはビジネスシーンでも利用頻度が高く、例えば機械学習アルゴリズムには詳しくないエンジニアやアナリストが、とりあえず現場のデータで精度が出るかやってみたい、という場合に使えそうです。
まとめ
以上、ハンズオンでは実際にAWS上で機械学習アプリケーションの学習とデプロイまでを行うことができました。
モデルの実装から推論用のエンドポイントの作成まで、特別インフラを意識する必要はありません。機械学習エンジニアにとってはよりアルゴリズム開発に集中できるのではないかと思います。
現在Google Cloud Platform上にも同様なサービスとして「Cloud Machine Learning Engine」がありますが、機能の違いなど比較すると面白そうです。
最後に、個人的に便利だと思った点をいくつか上げておきます。
- 単純にmanaged Jupyterとしても利用できる
- SageMakerはモデル実装から学習、デプロイまで一貫して行えるサービスですが、それぞれ一部だけ利用することもでき、Jupyter Notebookだけの利用も可能です。これを使えば簡単にGPUインスタンス上にJupyterを立ち上げてさっと使う、ということもできそうです。
- データの暗号化に対応
- 学習データ/推論結果も、プロダクションレベルにおいては高いセキュリティレベルでの取扱いを要求される場合も多く、データを暗号化する仕組みがサポートされているのは助かります。
注意点も上げておきます。
- 現在SageMakerは東京リージョンでは提供されていませんので、実際のサービスに組み込む際には留意しておく必要があるでしょう。
- Notebookインスタンス数など、SageMaker に利用するリソースはアカウントごとに上限が設定されています。もし社内で大規模に利用する場合には、事前に上限を上げる申請をしておく必要があります。(今回のハンズオンでも実施しました。) https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws_service_limits.html
以上.




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。