





はじめに
AIシステム部AI研究開発グループ アルバイトの五十嵐です。( @bonprosoft, ポートフォリオ: http://vbcpp.net/about/ ) 現在、東北大学大学院の修士1年で、大学院では(自然言語ではなく)高速な文字列処理アルゴリズムに関する研究を行っています。
私は2017年9月上旬から3週間ほど、アルバイト兼インターンとしてハッカドールチーム内のNLPのタスクに取り組んでいました。 その後はアルバイトとして、期間中にできなかった追加実験と実際の製品への適用に取り組んでいます。
取り組んだタスク
突然ですが、みなさま、ハッカドールはインストールされていますか? ハッカドールは、主にサブカルチャーに関する記事に特化した、ニュースアプリケーションです。 アプリケーション内のユーザーのクリックや「ホシイ/イラナイ」などのアクションを通して、ハッカドールがユーザーの好みを自動的に学習し、様々なジャンルの記事があるなかから、1日3回のおすすめ記事を配信してくれます。
さて、ハッカドールの裏側ではユーザーへ記事を配信するために日々膨大なWeb記事をクロールして、どの記事がどのジャンル・要素のものであるのかなどを識別し、検索サービスと同じようにユーザーへ記事を配信しています。Web記事を適切に解析するためには、毎クール増えるアニメのタイトルはもちろん、話題となっている単語にもいち早く対応しなければなりません。
そこでハッカドールチームでは、形態素解析のための辞書を毎日自動的に構築するジョブを用意しています。 これにより、大部分の解析処理はうまくいくようになりますが、まだいくつかの課題が残っています。 それは、シノニム辞書の構築です。 ここで言う「シノニム辞書」とは、アニメの作品名をはじめとした何らかの名称と略称/愛称を関連付けるための辞書のことを指しています。 シノニム辞書は、ハッカドール内において記事のタグ付けや検索において利用されています。有名な例としては、次のようなものがあります。
- ご注文はうさぎですか? ⇔ ごちうさ
- Re:ゼロから始める異世界生活 ⇔ リゼロ
- この素晴らしい世界に祝福を! ⇔ このすば
略称/愛称自体の分かち書きは、前述のジョブによりうまく動作しますが、その略称/愛称が指している名称との紐づけは現状自動的に獲得できておらず、この紐づけは現在手動で行っています。2017年10月現在、シノニム辞書に登録されたエントリ数は約5600件にも達し、日々増えていくシノニムを今後も管理し続けるのはとても大変な作業です。そこで今回は「シノニム辞書を何とか自動で獲得できないか」というタスクに取り組みました。
なお、シノニム辞書の自動構築にあたって、ハッカドール内で利用できるデータセットとしては次のようなものがあげられます。
- 日々のWeb記事のクロール結果
- アニメ/サブカルに関するタグ/キーワード集合
- 日々更新される形態素解析用辞書
- アプリ内の検索キーワード
- 現時点で登録されているシノニムペア
以降の章では、先行研究と提案手法、評価実験に関する詳細を説明していきますが、もし読むのが大変に感じる場合や先に成果物だけを見たい場合には、次のURLからスライドとデモサイトをご覧ください。
先行研究
最初の1週間は、今回のタスク設定と近い、同義語獲得/同義性判定関連の先行研究を調査しました。その結果、大きく分けて先行研究で用いられていた手法は、次の3種類に分けられると考えました。
- 単語表記を考慮した同義語判定
- 周辺文脈を利用した同義語判定
- 検索クエリなどの関係情報を利用した同義語判定
それぞれの手法において、特に印象に残った論文を、簡単にご紹介します。
単語表記を考慮した同義語判定
同義語がもともとの名称をベースに作られることを仮定すると、編集距離などの表記を考慮した手法を適用することを考えるのが自然です。2008年に高橋らが提案した手法[a]では、同義語を以下の3種類から生成されるものと仮定して、これらを考慮した同義語判定のためのフローおよび素性の作成を行っています。
- 定型文字列の追加: 接頭/接尾辞等の文字列を追加
- 表記変換: 読みを保存して表記を変換
- 省略: 文字順を保存して文字を削除
判定ルールのなかには、例えば音節数を考慮した正規化や、SVMを用いた省略関係にあるかどうかの判定ロジックが含まれており、2つの単語の単語表記について、様々な観点から距離を計算するための手法が組み込まれています。
周辺文脈を利用した同義語判定
「同じ文脈に出現する単語は類似した意味を持つ」という分布仮説(Harris, 1954)に基づいて、単語の意味を表すベクトルを求めるためのモデルとして、近年ではSkip-gramモデル(Mikolov+, 2013,[b])を用いた研究が活発に行われています。 ここではSkip-gramモデルの詳細の説明は割愛させていただきますが、原理を簡単に説明すると、ある単語を与えたときに、出力と周辺に出現する単語が一致する確率が高くなるように図1の$W_e$と$W$を学習することで、適当なイテレーションを回した後に得られる$W_e$が単語ベクトルとして利用できるという仕組みになっています。 なお以降の図では、Skip-gramモデルを図1右下のような、省略された図を用いて表現することにします。(図1右上と右下は等価なモデルを示しています。)
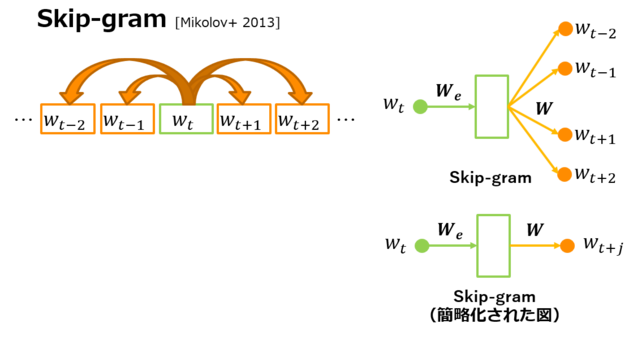
▲図1 Skip-gramモデル
Skip-gramモデルを利用した同義語獲得のアプローチとしては様々な手法がありますが、特に新しい手法として、城光らによって提案された、文脈限定Skip-gram(城光+, 2017,[c])があります。 この手法では、特定の品詞のみ/左右特定の位置のみを考慮するような制約を加えて、異なる制約を持った複数のSkip-Gramモデルを学習したあと、2つの単語ペアを与えたときに、これらのSkip-gramが出力するコサイン類似度を素性として、同義語か否かの教師あり学習を行っています。 論文中では、実際に合計254種類のSkip-gramを学習させたあと、これらのモデルを用いて同義語判定を行ったところ、通常のSkip-gramモデルだけの場合と比較して、F値が大幅に向上したと述べています。
検索クエリなどの関係情報を利用した同義語判定
同義語判定は検索エンジンにおいても重要となります。 2012年にMicrosoft Researchから発表された論文では、固有表現のシノニムを自動的に検出する手法に用いる指標の一つとして、Pseudo Document Similarity(Kaushik+,2012,[d])が提案されました。 この指標の前身となったClick Similarity(Cheng+, 2010,[e])は、2つのクエリの類似度を測るための手法として、検索クエリ集合とWebドキュメント集合を頂点とした二部グラフを考えたうえで、ある検索クエリからあるWebドキュメントにたどりついたときにエッジを張り、2つのクエリが与えられたときに、その値がどの程度一致するかという情報を用いています。 これに加えて、Pseudo Document Similarityでは、特に検索クエリが複数の単語からなる場合にもRecallがあがるよう、エッジの張り方を工夫しています。
先行研究の本タスクへの適用
先ほど挙げたそれぞれの手法を、今回のタスクへ適用することを考えてみます。はじめに次の例をご覧ください。
- 終末何してますか?忙しいですか?救ってもらっていいですか? ⇔ すかすか
- 僕は友達が少ない ⇔ はがない
この例は、近年放送されたアニメの作品名とそのシノニムのペアを示しています。 1番目の例は、すかが3回繰り返し出現しているにもかかわらず、シノニムはそのうちの2回から構成されています。 また、2番目の例では、有用と思われる名詞や形容詞、漢字表記などを無視して、シノニムは主に助詞から構成されています。
これは主観ですが、1クール毎に増えるアニメ作品名の略称の競合を避けるためにも、作品名からのシノニムの推測は年々難しくなっていると考えています。したがって、単語表記を考慮した同義語判定は、今回のタスクへ適用するのは難しいと考えました。
続いて、周辺文脈を利用した同義語判定ですが、単語分割さえできていればSkip-gramの学習が可能であり、周辺単語から単語自体が出現するコンテキストを推測する(単語表記を考慮しない)という性質から、今回のタスクにおいて応用可能であると考えました。 しかし、城光らの手法では、2つの単語がシノニムの関係にあるかどうかを判定するために、シノニムペアを教師データとして使用しており、教師データ作成のコストが必要です。 さらに、分類機の入力として合計254種類ものSkip-gramを用いており、この手法でモデルを頻繁に更新するのは難しいと考えました。
最後に、検索クエリなどの関係情報を利用した同義語判定ですが、今回のタスクへ適用するにはエッジを張るために必要な情報が足りません。 これは、検索クエリなどはデータセットに含まれるものの、その後のユーザーの行動に関する情報が含まれていないため、先行研究のようなエッジを張ることができないためです。 代わりに、検索クエリが文章に含まれているという関係をエッジとして使うことを考えましたが、この関係が果たしてどれくらい有効に働くかという点が見通せなかったため(3週間という限られた時間のなかで成果を出すため)今回はこの手法の採用を見送りました。 以上の理由から、今回のタスクは周辺文脈を利用した同義語判定ベースの手法で取り組みました。 しかし城光らの手法をそのまま適用することは難しいため、予備実験として、ひとまず従来のSkip-gramを学習させたうえで、何か改善できる点がないかを調べました。
予備実験
従来のSkip-gramを用いて単語ベクトルの獲得を行い、シノニムを与えたときのk近傍を観察してみます。
実験設定
学習に用いたデータセットとしては、Webからクロールした記事250,000件を使用しました。 このデータセットに含まれる単語数は533,999単語(のべ123,273,881語)です。
Skip-gramの学習に関する主要なハイパーパラメータとしては、窓幅を5単語、学習する単語ベクトルの次元を100次元としました。 また、ある単語の出現回数が全データセット中で5回より少ない場合には、その単語を学習から除外しました。 したがって最終的には、172,257単語(のべ93,799,316語)の単語を用いて学習を行いました。
実験結果
次の表は、学習済みモデルを用いて、アニメ作品のシノニムの単語ベクトルとコサイン類似度の高いベクトルを持つ5単語をそれぞれ列挙したものです。
表1 従来のSkip-gramを用いたときの、シノニムの単語ベクトルとコサイン類似度の近いベクトルを持つ上位5単語
| ごちうさ (ご注文はうさぎですか?) |
リゼロ (Re:ゼロから始める異世界生活) |
このすば (この素晴らしい世界に祝福を!) |
けもフレ (けものフレンズ) |
よう実 (ようこそ実力至上主義の教室へ) |
|
|---|---|---|---|---|---|
| #1 | リゼロ 0.71542 | ごちうさ 0.71542 | 幼女戦記 0.67590 | 二次創作 0.58515 | プリアラ 0.71460 |
| #2 | きんモザ 0.70086 | ガーリッシュナンバー 0.69933 | はいふり 0.65225 | エンドレスエイト 0.57156 | クロムクロ 0.66699 |
| #3 | まどマギ 0.67969 | 緋弾のアリア AA 0.66972 | ハルチカ 0.63882 | シュタゲ 0.55419 | ガーリッシュナンバー 0.63846 |
| #4 | ラブライブ 0.67866 | ワンパンマン 0.66917 | リゼロ 0.63733 | グレンラガン 0.54987 | えとたま 0.61215 |
| #5 | アイマス 0.67314 | 幼女戦記 0.66810 | 暗殺教室 0.63500 | ラブライブ 0.54697 | 正解するカド 0.60950 |
それ以外の単語で試した場合でも、上の表と同様にして、アニメタイトルを表す単語を与えた場合には、何らかのアニメタイトルを表す単語がk近傍に存在するという結果になりました。
しかし「ごちうさ」から「ご注文はうさぎですか?」、「リゼロ」から「Re:ゼロから始める異世界生活」が捉えられないことから、同一の作品を表すアニメタイトルの距離が近くなるように学習できていないことが分かります。 言い換えると、従来のSkip-gramでは、アニメタイトル同士は正しく距離が近くなるように学習されるものの、それ以上の特徴は捉えられていないということが分かります。(この結論は、一度でもword2vecを使ったことのある方なら、頷いていただけると思います。)
したがって、今回のタスクを解決するには、従来のSkip-gramでは難しいという結論になりました。
予備実験に関する考察
先ほどの表1をご覧ください。従来手法では「ごちうさ」に類似したベクトルを持つ単語として「リゼロ」が、また「リゼロ」に類似したベクトルを持つ単語として「ごちうさ」がそれぞれ出現しています。これは、学習の結果で得られた100次元のベクトル表現において「ごちうさ」と「リゼロ」がお互いに近い位置に存在するということを意味しています。では、なぜ「ごちうさ」と「リゼロ」が近くなるのでしょうか。 以降ではこの問題を、ごちうさ-リゼロ状態として呼ぶことにしましょう。
ごちうさ-リゼロ状態はなぜ起こるのか

図2をご覧ください。この表は、それぞれ「ごちうさ」「リゼロ」という単語の周辺5単語に出現する単語を、頻度を高い順にソートしたものです。
ところで、皆さんは、この表にあるような周辺単語の分布から「ごちうさ」「リゼロ」という作品名まで言い当てることができますか? (実際にアニメ作品名を知らせない状態で、作品の正式名称を除いた分布を与えて作品名を推測してもらったところ、あくまで主観ですが、半数程度の人が異なる作品名を答えていました。) 確かに作品を表すような特徴を持つような単語を含んでいるものの、基本的に確信を持って言えることは「アニメ作品」(もしくはサブカル全般)ということ程度かと思います。Skip-gramを含むWord2vecは、基本的にこのようなタスクを解くことを目標にして、単語ベクトルを学習しているのです。
さて、図2をよく観察すると、次のことが言えます。
- 「店舗限定」や「コラボ」などの、今回のタスクにおいてはノイズとなりそうな単語が上位に来ている
- 「アニメ」「キャラ」「イベント」などのアニメ全般で使われる単語が上位に来ている
この2点を手掛かりに解決策を探していきます。
まず一つ考えられる要因としては、複数作品に関して言及している記事が学習に含まれているという点です。 図3は、クロールされた記事に、アニメ/サブカルに関するタグ/キーワード集合(タスク設定の章で説明)を用いて付与されたキーワードの数に関するヒストグラムです。

キーワードを多く含むような記事としては、どのようなものがあるのでしょうか? 実際にデータセットを確認してみると、コミックマーケットをはじめとしたイベントにおける出展情報に関する記事が多く含まれていることがわかりました。「リゼロ」や「ごちうさ」のような人気作品はグッズも多く取り上げられることから、出展情報に関する多数のウェブページに出現しており、これが、ごちうさ-リゼロ状態の一つの要因になっているのではないかと考えました。
また二つ目に考えられる要因として、単語ベクトルの学習に周辺単語を使うだけでは、今回のタスクを解くには不十分であるという点です。 周辺単語を見ると、アニメ全般で用いられるような単語が多く出現していることがわかります。 これらの単語はWord2vecの学習において、一般名詞のなかからアニメ全般に関する概念を獲得する(アニメに関する単語の距離が近くなるように学習する)には重要ですが、今回のような、もう少し詳細にアニメ作品を考慮した単語ベクトルを獲得したい場合には、これらのアニメ全般用語は、いわばストップワードと同じ扱いになると言っても良いでしょう。
次の章では、アニメ作品に関するドメインの知識を考慮するような仕組みを組み込んだモデルを提案します。
提案手法
前述の要因二つについて、まず一つ目の解決策としては、前処理として1記事にキーワードを10個以上含む記事については除外を行いました。 これにより、なるべく1つの作品について言及しているようなWeb記事からのみ学習を行うようにするという狙いがあります。
二つ目に解決策ですが、学習モデルにこのキーワード情報をうまく埋め込むことで、アニメ作品に関するドメインの知識も単語ベクトルに埋め込むことができないかを検討しました。そこで考えたのが、以下の3つのモデルです。
モデル1号

モデル1号は、ある単語を入力としたときに、その周辺単語とドキュメントに付与されたキーワードを出力として学習を行うモデルです。 つまり、通常のSkip-gramモデルに加えて、キーワード情報を推測するような層を途中に付け足して、マルチタスク学習を行っています。
モデル2号

モデル2号は、ある単語と、その単語が出現するドキュメントに付与されたキーワード情報を入力としたときに、その単語の周辺単語を学習するモデルです。 これが学習できると、単語だけではなく、あるキーワードが出現するドキュメントにおいては、特定の単語が周辺に出現しやすいという、条件付きの周辺単語の推測もできるようになります。また、単語ベクトルの学習と同時に、キーワード情報に関するベクトルも学習できる点も魅力的です。
モデル3号
※こちらのモデルは、インターン期間終了後に追加実験として試したモデルです。
Rev. A

モデル3号 Rev.Aは、基本的にはモデル2号と同じです。しかし、モデル2号では1つのドキュメントに複数のキーワードが付与されていた場合に、そのSumを取って入力としていたところを、このモデルでは1つずつ入力として取るようにした点が異なります。 このように変更することで、モデル2号と比較して全体のモデル構成が浅くなり、学習が進みやすいのではないかと考えたためです。
Rev. B

モデル3号 Rev.Bは、Rev.Aに加えて、concatの後に1層のFully Connected層を挟んでいます。 これにより、例えば入力として与えられたキーワード情報が周辺単語の推測に役に立たないような場合でも、学習が可能になるのではないかと考えました。
Rev. C

モデル3号 Rev.Cは、Rev.Bに加えて、ResNet(He+, 2016,[f])で用いられているようなShortcut Connectionを加えました。 これにより、仮にキーワード情報を用いた場合のほうが性能が悪くなるような場合でも、最悪時の性能を通常のSkip-gramと同等くらいに保証できるのではないかと考えました。
キーワードのみSkip-gram
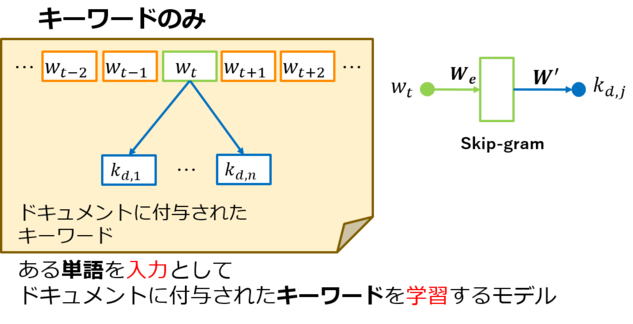
これは、モデル1号において、周辺単語への出力層を無くしたものと一致します。すなわち、マルチタスク学習の有効性を検証するために実験に用いたモデルです。
キーワードのみSkip-gramは、基本的にモデル構成はSkip-gramと同様ですが、ある単語を入力としたときに周辺単語を学習するのではなく、ある単語が出現するドキュメントのキーワード情報を学習している点が異なります。
評価実験
従来のSkip-gram、キーワードのみモデル、モデル1号~3号 Rev.Cまでをすべて実装し、評価実験を行いました。 なお、すべてのモデルはChainerを用いて実装しました。
実装は後日公開予定です。
評価手法
現在ハッカドールが持っているシノニムペア5600組を用いてモデルの評価を行うために、次の3つの評価手法を用いました。
- コサイン類似度
- K近傍一致度
- 相互ランク
コサイン類似度
コサイン類似度は、単純にシノニムペアがどれくらい近くなっているかを測定するための指標として取り入れました。
シノニムペアを$x, y$としたときに、コサイン類似度$cos(x,y)$は次のように定義されます。
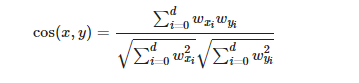
ここで、$w_x$は単語$x$の単語ベクトル、$d$は単語ベクトルの次元を示しています。
k近傍一致度
k近傍一致度は、シノニムペアとなる2単語の周辺に存在する単語がどれくらい一致しているかを測定することを目的として取り入れました。
シノニムペアを$x, y$としたときに、単語$x$(単語$y$)に対するコサイン類似度が高い上位$k$単語を集めた集合を$S_x $($S_y$)とします。 すなわち、すべての単語集合を$S$としたときに、$S_x$($S_y$)は次の2式を満たすように定義されます。
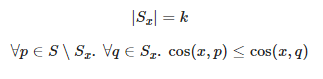
このとき、k近傍一致度$Jaccard_k(S_x, S_y)$は次のように定義されます。
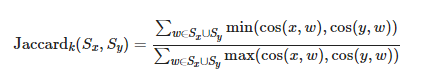
つまり、単語$x$と$y$のk近傍が、どれくらい一致しているかを重み付きのJaccard係数を用いて計算しています。
相互ランク
相互ランクは、単語$x$と単語$y$がどれくらい相互に近くなっているかを測定するための指標として導入しました。
単語$x$について、すべての単語とコサイン類似度を計算し、値の高い順にソートしたリストにおいて単語$y$が出現する順位を$ d_x\to y $とします。 単語$y$について、すべての単語とコサイン類似度を計算し、値の高い順にソートしたリストにおいて単語$x$が出現する順位を$ d_y\to x $とします。
このとき、相互ランク$rank(x, y)$は次のように定義されます。
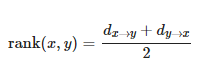
つまり、この値は単語$x$の類似単語を検索したときの単語$y$の順位と、単語$y$の類似単語を検索したときの単語$x$の順位の平均を示しており、この値が小さければ小さいほど良いモデルであると判断できます。
実験設定
学習に用いたデータセットとしては、Webからクロールした記事集合のなかで、1記事にキーワードを10個以上含まない記事集合から100,000件を使用しました。このデータセットに含まれる単語数は331,138単語(のべ49,187,387語)、キーワード数は47,751です。
Skip-gramの学習に関する主要なハイパーパラメータとしては、窓幅を5単語、学習する単語ベクトルの次元を100次元としました。 また、ある単語の出現回数が全データセット中で5回より少ない場合には、その単語を学習から除外しました。 したがって、最終的には、114,045単語(のべ37,128,122語)の単語を用いて学習を行いました。
同様にして、頻度が5回以下のキーワードについても除外しました。除外した結果、キーワードを含まなくなった記事については、特殊なキーワード(None)を与えました。したがって、最終的には、キーワード数は11,824となりました。
また、k近傍一致度で用いた$k$の値は20としました。 スコアには、シノニムペア5600組に対してそれぞれの評価手法を適用したときの値の平均を採用しました。ただし考察で述べる理由から、相互ランクにおいてのみ、中央値の算出も行いました。
実験結果
表2 モデルの評価結果
| モデル | コサイン類似度 | K近傍一致度 | 相互ランク(平均値) | 相互ランク(中央値) |
|---|---|---|---|---|
| 従来のSkip-gram | 0.4041 | 0.0660 | 9523.5263 | 892.0 |
| キーワードのみモデル | 0.5063 | 0.1918 | 5745.6675 | 22.5 |
| 1号 | 0.5293 | 0.1923 | 4926.6754 | 19.0 |
| 2号 | 0.3706 | 0.0532 | 14301.6743 | 2599.0 |
| 3号 Rev.A | 0.3348 | 0.0544 | 12626.5088 | 1696.0 |
| 3号 Rev.B | 0.3599 | 0.0616 | 11804.2098 | 1296.5 |
| 3号 Rev.C | 0.3585 | 0.0619 | 12003.0603 | 1292.0 |
実験結果から、従来のSkip-gramと比較すると、提案したモデル1号の性能は大幅に向上していることがわかります。では実際に、どのような出力がでるようになったかを実際に試してみましょう。
表3 モデル1号を用いたときの、シノニムの単語ベクトルとコサイン類似度の近いベクトルを持つ上位5単語
| ごちうさ (ご注文はうさぎですか?) |
リゼロ (Re:ゼロから始める異世界生活) |
このすば (この素晴らしい世界に祝福を!) |
けもフレ (けものフレンズ) |
よう実 (ようこそ実力至上主義の教室へ) |
|
|---|---|---|---|---|---|
| #1 | ご注文はうさぎですか? 0.87631 | Re:ゼロから始める異世界生活 0.78200 | めぐみん 0.84121 | たつき監督 0.73934 | ようこそ実力至上主義の教室へ 0.70415 |
| #2 | ご注文はうさぎですか?? 0.85684 | 長月達平 0.67824 | ダクネス 0.79038 | けものフレンズ 0.73272 | zitsu 0.57993 |
| #3 | チノ 0.82150 | エミリア 0.67667 | この素晴らしい世界に祝福を! 0.77038 | サーバルちゃん 0.72079 | 軽井沢 0.56846 |
| #4 | シャロ 0.75929 | レム 0.67260 | 駄女神 0.75584 | アライさん 0.69193 | 清隆 0.55031 |
| #5 | 千夜 0.74842 | MJ文庫J 0.64899 | カズマ 0.74682 | ドッタンバッタン 0.66814 | 綾小路 0.54770 |
表1と比較すると、既存手法に比べて、取りたかったものがだいぶ取れていることが分かります。ほかの例も試してみましょう。

図10の例では、様々な単語を既存手法と提案手法(モデル1号)に与えたときの類似5単語を示しています。 この例から、例えば「すかすか」→「週末なにしてますか?忙しいですか?救ってもらっていいですか?」といった既存手法では獲得するのが難しいと思われていたシノニムも正しく獲得できていることがわかります。 また「ほたるん」(のんのんびよりのキャラクターの愛称)を与えた場合に、既存手法ではキャラクターの語尾や一般名詞などが混在し、正しく距離を計算できていない結果となってしまっていますが、提案手法では同作品のキャラクターの愛称が近くなるようなベクトルが得られていることにも注目です。さらに「お仕事シリーズ」や「マスター」といった単語を与えた場合にも、ユーザーが想定しているであろう作品関連の単語が近くなるように学習されており、従来手法と比較すると、提案手法ではアニメタイトルやキャラクター同士が近くなるのはもちろん、作品なども考慮して距離が計算されるように制約がかかっているように見えます。
考察
相互ランクの値が大きいシノニムペアの特徴
はじめに、モデル1号について、実際にモデルに単語を与えたときの印象と比べて、評価データでの相互ランクの平均値が大きい(順位が低い)ことに注目しました。そこで、モデル1号の相互ランクのヒストグラムを求めた結果、次の図のようになりました。
図11から、一部の相互ランクの値が大きいシノニムペアに影響されて、平均値も大きくなっていることが推測できます。 これが、実験において相互ランクの中央値を求めた理由です。
では、モデル1号ではどのようなシノニムペアが相互ランクの値が大きくなっているのか(すなわち、正しく取れなかったのか)を考察してみます。評価データとして用いたシノニムペア 5600組のうち、モデル1号で相互ランクの値が大きかった(順位が低かった)シノニムペアを観察した結果、大きく分けて次の5種類に分類されると考えました。
- 表記ゆれによる単語の重複
- 評価データセットに古いデータが含まれている
- 評価データセットに一般名詞が含まれている
- 評価データセットにセリフ・その他が含まれている
- 同じ単語で複数の意味を持つ単語が存在
1番目の項目は、例えば「ニコ生」と「にこなま」のような単語です。 Web記事において出現する単語の数は、前者のほうが圧倒的に多く、後者が出現することはまれです。 つまり、前者は正しく学習することができますが、後者は正しく学習することが難しくなります。 このため、評価データに含まれる「にこなま」などの表記ゆれがある単語とのシノニムペアは、距離が離れてしまうと考えました。
2番目の項目は、例えば(「ワールドイズマイン」,「ワイズマ」)のようなシノニムペアが評価データに含まれているケースです。 今回の学習に用いたデータセットは、2014年3月~2017年9月の期間に公開された記事で構成されており、その期間より古いものや新しいもので出現するような単語については、正しく学習することが難しいという理由が考えられます。
3番目の項目は、例えば(「コメント」,「comment」)のようなシノニムペアが評価データに含まれているケースです。 今回の学習には、主にサブカル関係のWeb記事をデータセットとして用いており、マルチタスク学習にもアニメ作品関連のキーワードを利用しています。 そのため、一般名詞に関する順位は低いままでもおかしくないと考えました。
4番目の項目は、例えば(「イチロー」,「打ってみた」)のようなシノニムペアが評価データに含まれているケースです。 これらは主にニコニコ動画などのサービスで、動画のタグ機能として用いられているのをよく見かけますが、2番目の理由と同様にして今回の学習で獲得するのは難しいと考えました。
5番目の項目は、例えば「私モテ」や「とある」のような単語です。 例えば、前者の「私モテ」は「私がモテないのはどう考えてもお前らが悪い!」(2013年7月アニメ化)と「私がモテてどうすんだ」(2016年10月アニメ化)の2作品の愛称として知られています。 実際にGoogleで検索した場合にも、両方の作品が表示されていることがわかります。 後者の「とある」は、アニメ分野においては「とある魔術の禁書目録」「とある科学の超電磁砲」の2作品を指し、さらに一般的には連体詞として用いられています。
このような場合には、複数のコンテキストで同一の単語が出現することになり、正しく学習することが困難になります。 実は、このような曖昧性解消問題はアニメ関連においても深刻な問題となりつつあり、上記の作品名以外にも、例えば「凛」という名前が指すキャラクターが多い(有名なところでは「星空凛」「松岡凛」「遠坂凛」「渋谷凛」など)という問題があります。 このアニメドメインにおける曖昧性解消問題を凛状態と呼ぶことにしましょう。
凛状態の解決に向けて
では凛状態を解決するにはどうすれば良いでしょうか。
「どの凛を指しているかはキーワードと周辺文脈から区別できる」という仮定を置くと、次のナイーブなアルゴリズムを考えることができます。
- キーワードごとに異なる「凛」となるように区別
- 提案モデルを学習
- 1エポックごとに「凛」間の距離を測り、一定閾値以下であればマージ
- 2.へ戻る

3週間のうちに実際に実験することはできませんでしたが、上記のアルゴリズムを組み込むことで、適切にコンテキストの異なる同一単語を分離することができるのではないかと考えています。
モデル2号・3号の単語ベクトルのスコアが低い理由
従来のモデルとモデル2号・3号は、出力として周辺単語を予測するように学習を行っており、スコアの高いキーワードのみモデルとモデル1号は、出力としてキーワード情報を予測するように学習を行っています。 このことからも、評価実験でのスコアに大きく貢献したのは、キーワード情報からのロスであると考えることができます。
ところで、モデル2号と3号もキーワード情報をモデルの入力として用いています。この入力は、本当に無意味だったのでしょうか?
評価実験では単語ベクトル$W_e$のみを評価していたためスコアとしては現れていませんが、実はキーワードベクトル$W_e$にも面白い特徴が得られていました。モデル3号 Rev.Bの学習を通して得られた$W_d$に表1,3と類似したキーワードを与えると次の結果が得られました。
表4 モデル3号 Rev.Bを用いたときの、キーワードの単語ベクトルとコサイン類似度の近いベクトルを持つ上位5キーワード
| ご注文はうさぎですか? | Re:ゼロから始める異世界生活 | この素晴らしい世界に祝福を! | けものフレンズ | ようこそ実力至上主義の教室へ | |
|---|---|---|---|---|---|
| #1 | ココア 0.68947 | レム 0.78615 | めぐみん 0.83319 | サーバル 0.82906 | よう実 0.69769 |
| #2 | シャロ 0.67518 | エミリア 0.69870 | ダクネス 0.73124 | サーバルちゃん 0.77726 | セントールの悩み 0.55141 |
| #3 | ティッピー 0.56429 | 長月達平 0.66962 | 駄女神 0.61180 | ジャパリパーク 0.72899 | 恋と嘘 0.54268 |
| #4 | きんいろモザイク 0.51485 | スバル 0.3048 | ダークホース 0.60308 | けもフレ 0.72134 | 紗霧 0.53223 |
| #5 | のんのんびより 0.51027 | 鬱展開 0.56276 | 角川スニーカー文庫 0.56557 | かばんちゃん 0.71177 | 夏アニメ 0.48676 |
これもこれで面白い結果が出ていますね。 例えば「ご注文はうさぎですか?」に類似したキーワードとして「きんいろモザイク」や「のんのんびより」が出現している点や、「Re:ゼロから始める異世界生活」に「鬱展開」というキーワードが出現している点、さらには「ようこそ実力至上主義の教室へ」に類似したキーワードとして同時期に放送されたアニメなどが多数含まれている点など、何らかの知識が埋め込まれていると考えて良さそうです。
この結果から、モデル2号や3号においてモデルの学習に役立つアニメドメインに関する知識はキーワード情報からの入力を直接受け取る$W_d$が獲得しやすいため、$W_e$ではドメインに特化しない一般的な単語ベクトルの獲得が行われた、すなわち$W_e$にアニメドメインに関する知識の埋め込みが行われなかったのではないかと考えることができます。
これを踏まえると「なぜ1号のようにマルチタスク学習を行わなかったのか?」と疑問に思われる方も多いと思います。 実は今回の記事を執筆するにあたって間に合わなかったという理由もあるため、この実験は今後のタスクの1つでもありますが、実験を通して以下の2つの問題も出てくるのではないかと考えています。
- 入力と出力に同じデータが来るため、正しく学習されない可能性もある
- (他のモデルと比較して)学習時間が大幅に増加する
- 入力と出力のキーワード情報の組み合わせが二乗個になるため
モデルファイルとデモサイト
今回の取り組みで得られた単語ベクトルがどのようなものかを、実際に試せるデモサイトを次のURLで公開しました。
このウェブサイトでは、上部に単語を入力しEnterキーを押すことで、各モデルにおける類似度が高い単語(入力された単語のベクトルとコサイン類似度が高いベクトルを持つ単語)を検索することができます。利用できるモデルは次の通りです。
- Original Raw (250k, 100dim) : 従来のSkip-gram(250,000件のWeb記事を元に学習)
- Original (100k, 100dim) : 従来のSkip-gram (100,000件の前処理済みWeb記事を元に学習)
- Keyword Only (100k, 100dim) : キーワードのみモデル (100,000件の前処理済みWeb記事を元に学習)
- Model 1 (100k, 100dim/Best) : モデル1号(100,000件の前処理済みWeb記事を元に学習。提案モデルのなかで最も精度が高い。)
- Model 1 Large (1M, 300dim/Best) : モデル1号(1,000,000件の前処理済みWeb記事を元に学習。提案モデルのなかで最も精度が高い。)
- Model 2 (100k, 100dim) : モデル2号 (100,000件の前処理済みWeb記事を元に学習)
- Model 3 Rev.A (100k, 100dim) : モデル3号 Rev.A (モデル2号と同様)
- Model 3 Rev.B (100k, 100dim) : モデル3号 Rev.B (モデル2号と同様)
- Model 3 Rev.C (100k, 100dim) : モデル3号 Rev.C (モデル2号と同様)
また、学習済みの単語ベクトルも配布しますので、手元に環境がある方はこちらでも試してみてください。
なお、配布形式には次の3種類あります。
- tsv : 単語にスペースを含めることを許容するために、独自のフォーマットとなっています。単語と値の間がタブ区切りになっています。値はスペース区切りとなっています。
- Google-txt : Googleが公開したword2vec実装の出力形式(テキスト形式)に準拠しています。そのため、既存のword2vec実装で読み込むことができます。(単語と値の間がスペース区切りとなっています。そのため単語にスペースが含まれる場合(1つのエントリが複数語からなる場合)には、アンダーバー
_で置換されています。) - Google-bin : Googleが公開したword2vec実装の出力形式(バイナリ形式)に準拠しています。Google-txtと同様の処理が行われています。
まとめ
今回の3週間のインターンでは、アニメやサブカルに関連したシノニムの自動獲得タスクに取り組みました。 1週間目では、同義語獲得に関する先行研究の調査を行い、主な既存手法の要点を整理しました。 2週間目では、予備実験として、Skip-gramモデルを用いて現状のデータセットから単語ベクトルを学習し、得られた単語ベクトルから現状のタスクに適用する場合の問題点(ごちうさ-リゼロ状態)を調査しました。 また、予備実験で明らかになった問題点から、改善するための仕組みを取り入れたモデルを提案・実装し、評価実験を行いました。 評価実験の結果、提案モデルはアニメ作品に関する知識も同時に埋め込んだ単語ベクトルを獲得できることが明らかになり、従来のモデルよりも高い精度で今回のタスクを解くことが可能となりました。 3週間目では、これらの実験モデルに関する考察とデモの作成を行いました。 考察を通して、特に複数のコンテキストを持つ同一単語の単語ベクトルを学習することが困難である(凛状態)ことがわかり、アニメドメインにおける曖昧性解消の必要性について言及しました。
今回の提案手法によって得られた単語ベクトルの応用先の例として、ハッカドール内における検索システムで用いる同義語辞書などが挙げられます。 その理由として、例えばユーザーが「ごちうさ グッズ」のようなクエリで検索した場合に「(ごちうさ OR ご注文はうさぎですか? OR チノ OR ココア OR …) AND (グッズ OR トートバッグ OR …)」のように展開されたクエリで検索を行うほうが嬉しい場合もあるからです。
また、今回はキーワード情報としてアニメ関連の単語を使用しましたが、異なるドメインと関連した単語をキーワード情報として用いることで、別のドメインに関する知識を単語ベクトルに埋め込むことができると考えています。 例えば、料理やお店に関する情報をキーワードとして持っておき、これらの単語を文章のキーワード情報として与えることで、幅広い分野に本提案モデルを適用できるでしょう。
今後のタスクとしては、凛状態の解決とモデル2号・3号の性能改善などが挙げられます。
最後に、インターン開始前から業務内容をはじめ様々な点でお世話になりました、メンターの鴨志田さん、人事の戸上さん、山本さんに感謝いたします。 土田さん、濱田さんには特に研究を進めるうえで有益なアドバイスをいただきました。ありがとうございます。 本タスクに関して一緒にディスカッションしてくださった鈴木政隆さん、内田さんにも感謝いたします。
そして、今回のインターンを無事に終えるにあたって、さまざまな場所で支えてくださった、AIシステム部とハッカドールチームの皆様に、心から感謝いたします。
参考文献
[a] 高橋いづみ, et al. “単語正規化による固有表現の同義性判定.” 言語処理学会第 14 回年次大会発表論文集 (2008): 821-824.
http://www.anlp.jp/proceedings/annual_meeting/2008/pdf_dir/D4-5.pdf
[b] Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality
[c] 城光英彰, 松田源立, and 山口和紀. “文脈限定 Skip-gram による同義語獲得.” 自然言語処理 24.2 (2017): 187-204.
https://www.jstage.jst.go.jp/article/jnlp/24/2/24_187/_article/-char/ja/
[d] Chakrabarti, Kaushik, et al. “A framework for robust discovery of entity synonyms.” Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2012.
https://www.microsoft.com/en-us/research/wp-content/uploads/2012/01/idg811-cheng.pdf
[e] Cheng, Tao, Hady W. Lauw, and Stelios Paparizos. “Fuzzy matching of web queries to structured data.” Data Engineering (ICDE), 2010 IEEE 26th International Conference on. IEEE, 2010.
[f] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html




{kind=link}
最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。