





はじめに
皆さんこんにちは。DeNAのAI研究開発エンジニアの本多です。DeNAからは初日の Realtime Multi-Person Pose Estimation につづき2回目のChainer Advent Calendar への投稿となります。私は2017年よりDeNA AIシステム部にジョインし、以来コンピュータビジョンの研究開発に従事しております。 12/16に行われた 第43会CV勉強会@関東 にてICCV 2017現地レポートをさせていただいたこともあり、同学会でBest Paper Awardを獲得した’Mask R-CNN’ [1]を、chainercvをベースに実装してみることにしました。

背景
Mask R-CNNは、一つのネットワーク・モデルで、以下のような複数の情報を取得することのできるマルチタスク検出器です。
- 画像中の物体位置と大きさ (bounding box)
- 物体のカテゴリ (人なのか、ソファなのか)
- 物体のセグメンテーション (画素レベルでの物体位置)
- 人の体パーツ位置 (頭・肩・足など)
一枚の画像の各ピクセルをクラス分類するsemantic segmentationと異なり、本手法でのセグメンテーションは、オブジェクト毎の個別segmentationであることから、instance segmentationと呼ばれます。 例えば図1ですと、左の人と右の人は別のオブジェクトとしてsegmentationされています。ポーズ推定でも同様で、複数の人が別のオブジェクトとして認識されつつ、それぞれの体パーツの推定がおこなわれます。
このように、Mask-RCNNでは、画像内の物体領域を求め、それぞれの物体について個別に、詳細な情報を推論していくことができます。 今回は、chainercvのexampleに含まれており、Mask R-CNNの前身である Faster R-CNN をベースに、簡単な変更だけでMask R-CNNの機能を実装していきます。
ネットワークの構成
Mask R-CNNのネットワークは、Extractorと呼ばれる特徴抽出器と、物体の候補領域をピックアップするRegion Proposal Network、そして各タスクに対応するheadと呼ばれる子ネットワークから構成されます。
①class and box head
②mask head
①はFaster R-CNNに含まれており、ピックアップした候補領域を1次元ベクトルに変換したのち、全結合ネットワークによりクラス分類、及び物体の境界であるbounding boxの位置を出力します。今回追加するのは②、すなわちセグメンテーションマスクを推定するためのheadネットワークのみです。

データセットの読み込み
学習にはCOCO dataset 2017のtrainを用います。 COCO datasetは、80のオブジェクト分類及び位置、セグメンテーションマスク、人に関しては体パーツ位置など、多くのアノテーションが付与されたデータセットで、13万枚程度の学習用画像が含まれます。データセットをサンプルする関数であるget_exampleが返すのは、画像と、bounding box、ラベル、そして上記 セグメンテーションマスク の4つとなります。
ここでは、セグメンテーションマスクの読み込みについて説明します。 マスク情報は、ポリゴン座標のリストという形でアノテーションデータに含まれています。ある画像に対するセグメンテーション情報をseg_polygonsに読み込んだのち、
mask_in = np.zeros((int(h), int(w)), dtype=np.uint8)
for annot_seg_polygon in annot_seg_polygons:
N = len(annot_seg_polygon)
rr, cc = polygon(np.array(annot_seg_polygon[1:N:2]),
np.array(annot_seg_polygon[0:N:2]))
mask_in[np.clip(rr,0,h-1), np.clip(cc,0,w-1)] = 1のようにして、ポリゴンをセグメンテーションマスクに変換しながらmask_inに格納していきます。ここで、マスクはバイナリで、‘1’が物体のある場所を表します。ここでh,wは画像のサイズと同じです。
モデルの実装
実装は、chainercvのexamplesに含まれているfaster_rcnnをベースに行っていきます。
1.ExtractorとRegion Proposal Network
まず入力画像からfeature map (特徴マップ)を抽出します。
features = self.mask_rcnn.extractor(imgs)ここでextractor(抽出器)は、mask_rcnnクラス内で
extractor = VGG16(initialW=vgg_initialW)のように定義されています。今回はchainercvのFaster-RCNNに倣い、VGG16の5回目のmax poolingの直前までをextractorとして使用します。他にResNet等を使用することもできます。抽出されたfeature mapのサイズは元画像の1/16になります。
次にRegion Proposal Networkを適用し、物体の存在する領域(Region of Interest, ROI)を抽出します。chainercvの region_proposal_network.py を変更なく用いています。
2.教師マスクデータ
次に抽出されたROIに対し、ground truth (教師データ)を設定します。 chainercvの proposal_target_creator.py では、抽出されたROIそれぞれとオーバーラップの大きいground truthオブジェクトを見つけ、gt_assignmentというインデックスで関連づけています。これを利用して、マスクデータの読み込みを追加します。
gt_roi_mask=[]
for i , idx in enumerate(gt_assignment[pos_index]):
A=mask[idx, np.max((int(sample_roi[i,0]),0)):np.min((int(sample_roi[i,2]),h)),
np.max((int(sample_roi[i,1]),0)):np.min((int(sample_roi[i,3]),w))]
gt_roi_mask.append(cv2.resize(A, (masksize,masksize)))ground truthマスクは、図3のように、positiveとなったROIに相当する領域sample_roiで切り出されます。ここでROIの大きさはそれぞれ異なるのですが、正解データは全て(masksize,masksize)に固定します。masksizeは例えば14です。

ROIの切り出し方法については、本論文では新しく導入されたROI alignという手法により精度良く切り出しを行っています。本稿では簡単のため、Faster R-CNNで用いられており、chainerにも実装されているROI poolingを用います。ROI alignとROI poolingの違いについては、[2]をご参照ください。
3.Headネットワーク
ROI poolingで切り出されたfeature mapのサイズは、128(候補数) x 512 (channel数) x 7 x 7 (ROI大きさ)となっています。これを、各head networkに入力していきます。
ネットワーク定義は
- class and box head (Faster R-CNNと同じ)
#Faster-RCNN branch
self.fc6 = L.Linear(512*roi_size*roi_size, 4096, initialW=vgg_initialW)
self.fc7 = L.Linear(4096, 4096, initialW=vgg_initialW)
self.cls_loc = L.Linear(4096, n_class * 4, initialW=vgg_initialW)
self.score = L.Linear(4096, n_class, initialW=score_initialW)- mask head (今回追加。サイズは7 x 7 から 14 x 14 に拡大される)
#Mask-RCNN branch
self.convm1_1 = L.Convolution2D(512,512,3,1,pad=1, initialW=None)
self.convm1_2 = L.Convolution2D(512,512,3,1,pad=1, initialW=None)
self.deconvm1 = L.Deconvolution2D(512, 256, 2, 2, initialW=None)
self.convm2_1 = L.Convolution2D(256, 256, 3, 1, pad=1,initialW=None)
self.convm2_2 = L.Convolution2D(256, n_class, 3, 1, pad=1,initialW=None)ネットワークのforward実行は
- class and box head
fc6 = F.relu(self.fc6(pool))
fc7 = F.relu(self.fc7(fc6))
roi_cls_locs = self.cls_loc(fc7)
roi_scores = self.score(fc7)- mask head
h = F.relu(self.convm1\_1(pool))
h = F.relu(self.convm1\_2(h))
h = F.relu(self.deconvm1(h))
h = F.relu(self.convm2\_1(h))
masks=self.convm2\_2(h)のように行います。
4.損失関数
mask headのLoss(損失)計算のため、mask headの出力であるroi_cls_mask : 128(候補数) x 81(クラス) x 14 x 14 (マスク大きさ)から、対象ROIに存在する正解ラベルに該当するroi_mask :128(候補数) x 14 x 14(マスク大きさ) を抽出します。
roi_mask = roi_cls_mask[self.xp.arange(n_sample), gt_roi_label]そして、同じく候補領域のground truth maskであるgt_roi_maskと比較し、損失を求めます。
mask_loss = F.sigmoid_cross_entropy(roi_mask[0:gt_roi_mask.shape[0]], gt_roi_mask)ここでground truthは0 or 1 のバイナリで、ネットワーク出力は正負の値を持つfloat値です。損失関数としては、sigmoid cross entropyを用います。 これでmask lossが定義できました。Faster R-CNNのlossに、mask_lossを加えてできあがりです。論文で記載されているloss式に倣い、各lossの重み付けは行っていません。
loss = rpn_loc_loss + rpn_cls_loss + roi_loc_loss + roi_cls_loss + mask_loss学習
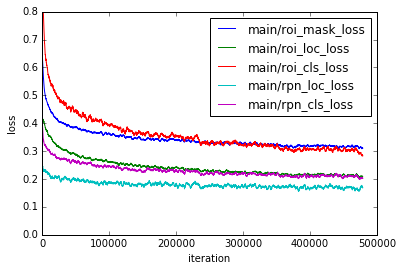
さて、いよいよ学習です。COCO datasetは大きいので、epochでなくiterationで管理します。図4のように、およそ40万iteration (それでも3 epoch!)程度でlossの値が安定します。train lossの内訳を見ると、各lossの絶対値は異なりますが、mask loss (roi_mask_loss)も比較的初期段階から下降していきます。 セグメンテーションマスクの学習は、前述のように、候補領域に存在するオブジェクトの正解ラベルと正解マスクを用いて行われます。したがって、正確にラベル予想ができるようになる前(roi_cls_lossが下がる前)でもセグメンテーションの学習が進んでいると考えられます。
推論
推論の実装では、学習に用いたネットワークの出力に若干の「後処理」を加えています。 Non Maximum Supression (NMS)、およびセグメンテーションマスクの表示です。 NMS処理は、推定したBounding Boxのうち、信頼度の高いものだけを残して、それらにオーバーラップするものを排除する処理で、 chainercvのNMS実装 をそのまま用いています。
セグメンテーションマスクは、我々の実装では、簡単に
for my in range(mask_size):
for mx in range(mask_size):
mxy = (bb[1]+width/14*mx, bb[0]+height/14*my)
Mcolor=np.clip((M[my,mx])*1,0,0.5)
ax.add_patch(plot.Rectangle(mxy, int(width/14)+1,int(height/14)+1,
fill=True, linewidth=0,facecolor=COLOR[i%len(COLOR)], alpha=Mcolor))のように、Bounding Box(‘bb’)内を(mask_size(=14), mask_size)に分割して、maskネットワークの出力’M’に応じて四角形をアルファブレンドしていきます。簡易な表示方法ですが、人物のセグメンテーションが個別に行えていることがわかります。色はパレットを作り、オブジェクト毎にランダムに選定しています。

まとめ
今回はICCV'17 Best PaperであるMask R-CNNの機能を、chainercvに追加するかたちで再現してみました。 実装は こちら にて公開しています。ぜひお試しください!
参考文献
[1]K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask R-CNN. In ICCV, 2017.
[2]yu4u, 最新の物体検出手法Mask R-CNNのRoI AlignとFast(er) R-CNNのRoI Poolingの違いを正しく理解する.
https://qiita.com/yu4u/items/5cbe9db166a5d72f9eb8




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。