





はじめに
皆さんこんにちは。AIシステム部・AI研究開発グループの李天琦( leetenki )です。
先日Amazon EC2 P3インスタンスがリリースされるに伴い、11月9日にアマゾン東京本社にて、「Amazon EC2 GPU インスタンス 祭り」というイベントが開かれました。それに先駆けて、弊社AIシステム部では特別に先行でP3インスタンスを使用させて頂き、速度性能の評価を行いました。また、イベントでのお客様企業による登壇セッションでもその内容について発表させて頂きました。本記事でその評価結果について紹介しようと思います。

Amazon EC2 P3インスタンスとは
Amazon EC2 P3は、NVIDIA Tesla V100世代のGPUを搭載した最新のインスタンスです。GPUベースの並列コンピューティング機能を兼ね備え、CUDAやOpenCLを使用するGPGPUコンピューティング用途向けに設計ています。特に高い浮動小数点演算処理能を必要とする機械学習、Deep Learning用途に最適化されています。
2017年11月時点において、Amazon EC2で提供されているオンデマンドタイプのGPUインスタンスのうち、P3シリーズのインスタンスは下記の3種類です。全てTesla V100モデルのVoltaアーキテクチャのGPUを搭載しています。GPUの数やGPUメモリサイズ、CPUの数やCPUメモリサイズ等の細かい違いがあります。
| GPUs | GPU Memory | CPUs | Main Memory | |
|---|---|---|---|---|
| p3.2xlarge | 1 | 16 | 8 | 61 |
| p3.8xlarge | 4 | 64 | 32 | 244 |
| p3.16xlarge | 8 | 128 | 64 | 488 |
検証環境
今回速度性能評価を行う上で、比較をシンプルにするために、以下の1GPUのみのp3.2xlargeタイプのインスタンス、及びこれに対応する1世代前のp2.xlargインスタンスを使用しました。
| GPUs | GPU Memory | CPUs | Main Memory | |
|---|---|---|---|---|
| p2.xlarge | 1 | 12 | 4 | 61 |
| p3.2xlarge | 1 | 16 | 8 | 61 |
また、OS及び各種ライブラリ環境はどちらも以下のように統一させました。
| OS | Ubuntu16.04 |
|---|---|
| CUDA | 9.0 |
| cuDNN | 7.0 |
| chainer | 3.0.0 |
| cupy | 2.0.0 |
検証用モデル
自分はAIシステム部内ではComputer Visionチームに所属しているという事もあり、今回は普段から業務で使っているCNN(Convlutional Neural Network)について速度検証させていただきました。具体的には、以下に述べるVGG19及び、Pose Estimationのネットワークを使用しました。
VGG19速度比較
Computer Visionのタスクを解く上で、よく使われるCNNモデルにVGG19というのがあります。これは元々、画像認識の世界的なコンペティションであるILSVRC2014において、Classification Taskの分野で世界一の精度を記録したモデルです。最近ではClassification Taskだけでなく、様々な高度なCNNモデルのベースの特徴抽出器としても使われています。そのモデル構造は非常にシンプルで、下図のように3×3のConvolution層及びPooling層のみから成り立っています。

今回VGG19の計測を行うために、元々p2インスタンス上で動かしていたコードをそのままp3インスタンスに持ってきて速度比較を行いました。本来ならば、Tensorcoreを発動させるのにp3用にソースコードをFP32からFP16に書き換えるのが望ましいですが、今回はChainerの開発ブランチが上手く動作せず、そちらについては断念しました。
以下が、p2及びp3上におけるVGG19モデルの動作速度の比較になります。このグラフでは、VGG19を1回推論処理するのに必要な平均時間を示しています。
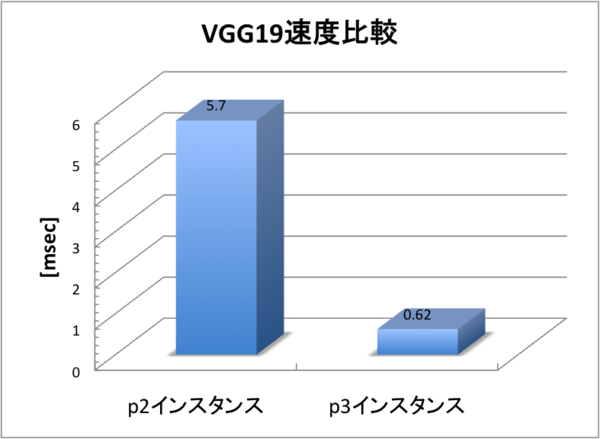
VGG19を1回推論処理するのに、p2インスタンスでは5.7[msec]かかっていたのが、p3インスタンスでは0.62[msec]と約9〜10倍高速化される結果となりました。 なぜTensorcoreを発動せずともこのように高速化できたのかについて、詳しく調べるためにNVIDIA Profilerを使ってプロファイリングしてみました。
まずp2インスタンスについて、下図のように、処理中はGPU使用時間の約70%をimplicit_convole_sgemmというcuda関数が占めています。これは簡単に言えば、cudaを使ったconvolution層の畳み込み演算を行う関数です。

一方で、p3インスタンスの処理結果を見てみると、同じようにconvolution処理を行なうのに、implicit_convole_sgemmではなく、winograd3 × 3Kernelというcuda関数が呼び出されています。
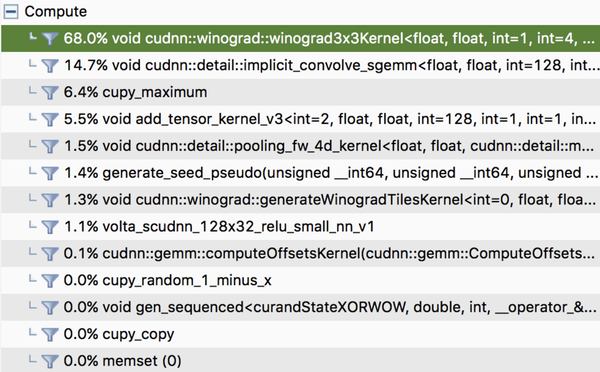
このwinogradが何かと言うと、convolutionのカーネルサイズが小さい時(3 × 3等)に、畳み込み演算を高速化するアルゴリズムです。VGG19のモデルでは全てのconvolution層のカーネルサイズが3 × 3となっているので、このwinogradアルゴリズムにより大幅に高速されたという訳です。しかし、このwinogradアルゴリズムは実はKepler世代より前のGPUには対応していないため、今回はp3インスタンス上でのみ発動し、このwinogradアルゴリズムの差、及び元々のGPUパワーの差が効いて、9倍高速されたと推測できます。
Pose Estimation速度比較
次にPose Estimationについて速度比較を行います。このPose Estimationという技術を簡単に説明すると、RGBの2次元動画像から、映っている人の細かいPoseを推測する技術です。下図のように、実際に我々が開発を進めているスマートショップというプロジェクトでもこの技術を活用しています。

アルゴリズムの詳細については元論文を参照して頂ければと思いますが、このアルゴリズムのモデル構造は非常にシンプルです。下図にあるように、ネットワーク構造は1 × 1、3 × 3、7 × 7のConvolution 及びPooling Layerのみで構成されています。

入力画像を、まずはVGG19とほぼ同じ構造のCNNに通して、解像度を8分の1に圧縮した特徴マップを抽出します。その後段で2つのブランチに分岐し、1つはConfidence Mapsと呼ばれる、体の各key pointをheatmap形式で予測するネットワークです。下図のように、key pointの種類ごとに1channelの出力で予測します。

もう一つのブランチが、PAFs (Part Affinity Fields) と呼ばれる、各key point間の繋がりうる可能性を表すベクトルマップを予測するネットワークです。

これら2つのブランチでConfidence Maps及びPAFsをそれぞれ予測した後、さらに予測した結果に最初のVGG19で抽出した特徴マップをconcatして、これを再度同じ構造のネットワークに繰り返し入力していきます。この繰り返しのネットワークをstageと言い、stageが進むほど精度があがる仕組みです。
このPose Estimationのモデルに関してはstageごとに推論速度の比較を行いました。以下が比較結果になります。
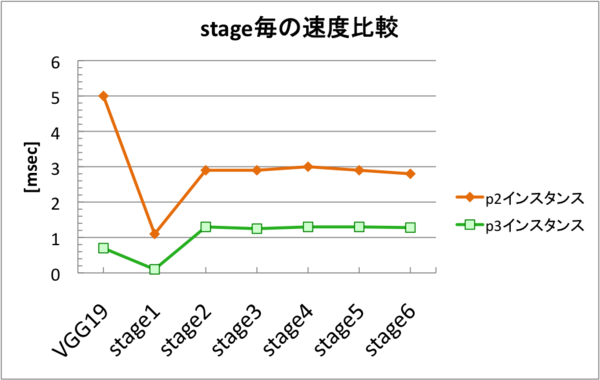
こちらの比較結果を見ると、最初のVGG19の処理部分では、p3インスタンスのほうが約8〜9倍高速化できている事がわかります。また、その次のstage1でも、p3インスタンスのほうが約7倍高速化されています。しかし、stage2以降では差が縮まり、約2.3倍しか高速化されない結果となりました。
これについてもプロファイリングしてみたところ、winogradアルゴリズムが関係している事がわかりました。先ほど説明した通り、winogradというのはconvolutionのカーネルサイズが小さい時(3 × 3等)に、畳み込み演算を高速化するアルゴリズムです。今回使用したPose Estimationのモデルでは、最初のVGG19及びstage1の部分では全てカーネルサイズが3 × 3のconvolution層で構築されているため、p3インスタンスのほうでwinogradが発動して7〜9倍高速化された訳です。しかし、stage2以降ではほとんどのconvolution層がカーネルサイズ7 × 7に置き換わるため、p3でwinogradを発動させる事ができず、GPUパワーの違いのみで、そこまで大きく速度差が開かなかったと考えられます。
Batch処理の速度比較
以上のpose estimationの推論速度の比較を行ったところ、winogradが発動しない場合はGPUパワーのみの違いで約2〜3倍しか差が開かない事がわかりました。しかし、GPU使用率を見てみると、p2インスタンスではGPU使用率100%といっぱいいっぱいなのに対し、p3インスタンスではGPU使用率が34%とまだかなり余裕があるように思えます。
そこで、Batch処理を行って、どちらもGPU使用率を100%まで使い切った状態で速度比較を行いました。下図が、batchサイズを増やした際のp2インスタンス及びp3インスタンスの推論処理時間になります。
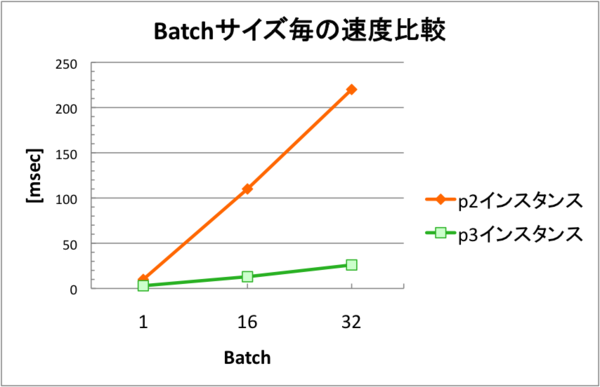
batch size 1の時ではp3インスタンスのほうが処理速度3.7倍(stage 2までのトータル処理速度)だったのに対し、batch sizeを大きくしていけば行くほど処理速度の差が開いていく結果になりました。グラフにあるように、p2インスタンスではbatch sizeを32倍にすると処理速度もそれに比例して約30倍ほど遅くなるのに対し、p3インスタンスではbatch sizeを32倍にしても処理速度は約8〜9倍しか遅くならないという結果となりました。倍率で言うと、batch size 32で処理した場合はwinogradの発動しないstage2以降でも、p3インスタンスのほうが8倍以上高速化可能という事になります。
ちょうど、今までp2インスタンス上でリアルタイムのPose Estimationを行うのに約3〜4FPSとフレームレート的にカクカクだったので、これをp3インスタンスに置き換えれば30FPSと完全にリアルタイムで処理できるという事になります。
訓練速度比較
ここまで推論の話を書いてきたので、訓練についても速度比較を行ってみます。ここでは、Pose Estimationのモデルをフルスクラッチで訓練させ、1回の順伝搬及び逆伝搬にかかったイテレーション時間を計測します。なお、batch sizeはGPUメモリの都合上どちらも16とします。
以下が訓練における速度比較結果になります。p2インスタンスでは1回のイテレーションを行うのに9.8秒かかったのが、p3インスタンスでは1.3秒と約7.5倍高速化された結果となりました。ちょうど今までp2インスタンスでの訓練に1週間ほどかかっていたのが、1日で完了するので実用的にはかなり嬉しいですね。
| 速度 | |
|---|---|
| p2インスタンス | 9.8[sec/iter] |
| p3インスタンス | 1.3[sec/iter] |
コストパフォーマンス比較
今回速度比較に用いたp2.xlarge及びp3.2xlargeインスタンスについて、東京リージョンの価格を比較してみます。
| 価格 | |
|---|---|
| p2.xlarge | $1.542/hour |
| p3.2xlarge | $5.243/hour |
このように、コスト面ではp3.2xlargeのほうが約3.4倍高くなっています。しかしこれまで説明した通り、p2インスタンス上で動いていたコードに特に変更を加えなくとも、そのままp3インスタンスに持って行けば約7〜9倍高速化できるので、値段の割にコスパはかなり良いと思います。そして今回は残念ながら触れられませんでしたが、Volta世帯のGPUの目玉機能であるTensorcoreが発動するようコードを修正すれば、更に10倍速以上の高速化が期待できますので、機会があればそちらにもチャレンジしてみようと思います。
おまけ
おまけですが、今回p2及びp3インスタンスの速度比較に使用したPose Estimationのソースコードについて、 こちら でオープンソース公開していますので、皆さんもし良かったら試してみてください。
参考文献
・Zhe Cao and Tomas Simon and Shih-En Wei and Yaser Sheikh. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In CVPR, 2017. arXiv:1611.08050 [cs.CV].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。