





システム本部SWETグループの薦田(こもだ、と読む)です。SWET(スウェット、と読む)はE2Eテストの自動化を中心にDeNAの事業の開発生産性と品質の向上をミッションとするチームです。
SWETでは社外における新しいテスティング技術をウォッチし発信していくこともそのミッションの一つとなっています。そのような活動の一貫として、3月13日から17日にソフトウェアテストに関する国際会議 ICST 2017 に参加してきました。
ICST 2017での発表内容は大学での研究が中心でしたが、Googleやトヨタ自動車など産業界のテスト・エンジニアの参加も多かった印象です。会議期間中は発表セッションだけでなく、休憩時間や会場の通路などで、産業界からの参加者とアカデミックからの参加者が入りまじり、プログラミング教育におけるテストの位置づけの話から泥臭いテスト実装のケーススタディまで幅広いトピックについて、熱い議論が行われていました。
ICST 2017全体のスコープはソフトウェアテスト全般です。必ずしもモバイルアプリケーションやウェブアプリケーションだけがターゲットというわけではなく、車載向けシステムの検証の話やファクトリ・オートメーションの話などもあり、普段聞けないような話を聞くことができるのは、大きな魅力と感じました。
さて今回はそうしたICST 2017の発表の中でも、SWETの業務と特に関連が深いウェブアプリケーションのUI自動テストに関する「Using Semantic Similarity in Crawling-based Web Application Testing」というタイトルの、カリフォルニア大学アーバイン校Jun-Wei Lin氏の発表について紹介させていただきます。
フォーム入力自動化における実装上の課題
論文の内容について紹介する前に、弊社内でのこれまでのUI自動テスト開発の経験の中で上がっていた課題について説明させていただきます。
ウェブアプリケーションを対象にE2EのUI自動テストを書くとして、例えばログインページにメールアドレスとパスワードを入力する、という操作を自動化することを考えます。 この処理の実装としてよくあるのが、例えば以下のような実装です。
# テスト対象のログインページに移動
visit "https://test-target.com/login"
## nameが"emailAddress"であるフォームにemailを埋める
## この値は、テスト対象ページの実装依存
fill_in "emailAddress", with: "hogehoge@fuga.com"
## nameが"passwd"であるフォームにパスワードを埋める
## この値は、テスト対象ページの実装依存
fill_in "passwd", with: "password"
## idが"btnNext"であるボタンを見つけてきて、クリックする
find('#btnNext').clickテスト対象ページのHTMLタグのidやnameの値をハードコードして、そこに特定の値を入力するという実装です。
このような実装では、テスト対象画面の入力フォームのidやnameの値をテストコード側で管理しなくてはなりません。テスト実行に必要なテスト対象固有のデータのことをテストアセットと呼びますが、テストの規模が大きくなってくるとこのテストアセットの管理が複雑になるという問題があります。
さらに悪いことに、HTML内のidやname属性の値は、テスト対象のHTMLの変更によって容易に変わってしまうものです。実際に弊社内で運用しているUI自動テストでも、HTMLの変更によってユーザから見れば全く問題がないにも関わらず、リグレッションテストが失敗することがしばしば起こります。リグレッションテストを利用するエンジニアはテストの実装者と異なる場合も多く、このようなUIテスト実行失敗の原因をシューティングすることは時間がかかり面倒な作業となっているのが現状です。
今回紹介する論文「Using Semantic Similarity for Input Topic Identification in Crawling-based Web Application Testing」では、このようなフォームの自動入力処理の実装に自然言語処理の手法を適用することで、テスト実装とテスト対象システムの実装を疎結合化し、テスト対象システム内の特定のHTML属性値に依存しないロバストなフォーム入力の自動化を実現する、という内容です。
フォーム入力自動化への自然言語処理の適用
この論文の中心となるアイディアはフォーム入力自動化を、HTMLタグをその意味ごとに分類するという機械学習の分類問題として取り扱ってみようというものです。機械学習によってテスト対象ページにあるフォームの意味が分類できれば、idやname属性の具体的な値をテスト側で知らずとも、 フォームを埋めることができます。例えば、ログインページであればページ内に存在する入力フォームを、1.ログインID、2.パスワード、3.ログインとは関係のないフォーム、の3種類に分類できれば良いといった具合です。
さてこの論文中では、フォームの実体であるHTMLを機械学習、特に自然言語処理の枠組みで扱うために少し工夫をしています。具体的には、各フォームに対応するHTMLタグを以下のように変換してしまいます。
変換前のHTMLタグ
<input type="email" id="subject-id" name="subject_id" autocomplete="on" placeholder="メールアドレス" class="txtfield w-max" value="">
変換後の単語列
["email", "subject", "id", "subject", "id", "メールアドレス", "txtfield", "w-max"]
この変換は単純に<input>タグの属性値を抜き出して単語ごとに区切っただけですが、論文中ではフォーム周辺の文字列を単語列に含めるなど、もう少し賢い変換を行っていますが本質は同じです。このような変換をかませることで、既存の自然言語処理の文書分類手法を、そっくりそのままHTMLに対して使うことができるでしょう、という点がこの論文の2つ目のアイディアです。
実験
この手法について、簡単な再現実験も行ってみましたのでその結果も報告させていただきます。
具体的には、DeNAの提供するいくつかのサービスのログインページに対して、出現する<input>タグを分類して、ログインIDを入力するフォーム、パスワードを入力するフォームを判別できるかどうかを試してみました。
詳細
グーグルで「ログイン」で検索して出てくる上位の41のサイトのログインページのHTMLから、
・<input> タグを抽出し
・これらの<input> タグがログインIDなのか、パスワードなのか、ログインと関係ないタグなのかを手動でラベル付けした
ものを学習データとして利用しています。 学習データは合計218個のフォームで、ラベルの分布は

のようになっています。
・文書のベクトル表現にはBag of Wordsを用いている
・文書ベクトルはLSI(潜在意味解析)による次元圧縮を行ったのち、ロジスティック回帰を用いてラベル推定を行っている
アルゴリズム実装にはPythonの機会学習ライブラリ gensim を用いました。
また、モデルの精度を評価するためのテストデータはいくつかの弊社サービスのログインページ内の10のフォームに対して検証を行っています。

実験結果
検証実験の結果は以下のようになります。ログインIDに対するPrecision、Recall、パスワードに対するPrecision、Recallおよび全体のAccuracyを評価しています。
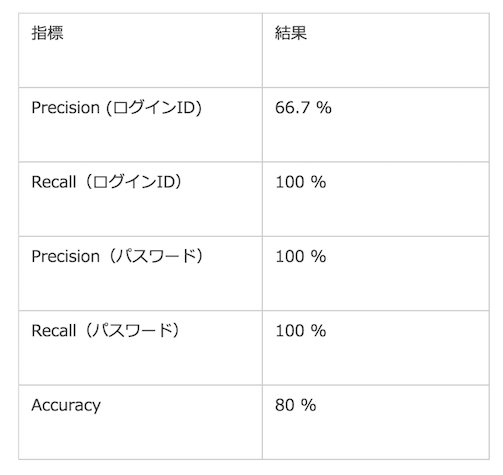
データ数が小さいので確定的なことを述べるのは難しいですが、なんとなくうまくいっていそうです。再実行が簡単にできるUI自動テストというユースケースを考えると、Precisionが低いことはある程度許容できること、また本当は入力対象のフォームだったが推定時に取りこぼしてしまったケースがなかったこと(Recall 100%)を考えると実用的に利用できそうな気もしてくる結果です。
さて、誤判定をしている2つのケースですがこれはどちらも、本当はログインIDではないフォームを、ログインIDフォームとして誤判定しています。具体的にには、例えば以下のようなものでした。
<input type="email" id="register-subject-id" name="subject_id" autocomplete="on" placeholder="メールアドレス" class="txtfield w-max" value="">
このフォームタグがあるログインページは
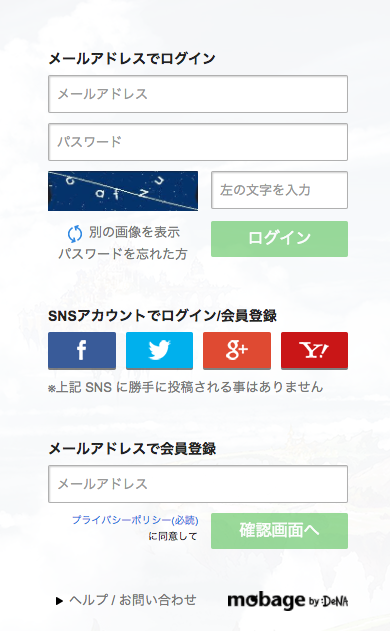
のような画面です。
このログインページには「メールアドレスでログイン」と「メールアドレスで会員登録」の2つのメールアドレス入力欄がありますが、今回の実験ではこの2つのフォームをどちらもログインID用の入力フォームと判定しています。本物のログインIDフォームの属性値と会員登録用フォームの属性値はほとんど同じであり、このケースは<input>タグの属性値のみを用いて判別するのは難しかった例と言えるかと思います。
今回の実験では簡単のため、原論文の実装とは異なり<input>タグ内部の属性直のみを用いていました。これを原論文と同じように各フォームの周辺のHTMLタグの値(ラベルの値など)を学習・推定に用いれば、このような誤判定も解決できるかもしれません。
まとめ
今回はICST 2017で発表された「Using Semantic Similarity in Crawling-based Web Application Testing」という論文について紹介させていただきました。再現実験では、とても単純な例とはいえ、UI自動テストへの機械学習適用の可能性を感じさせる結果を得ることができました。
本当にこのような手法がうまくいくのであれば、フォーム入力の自動化だけでなく自動テスト実装の様々な場面で利用することができると考えられ、より実践的なユースケースでの実験を引き続き進めていく予定です。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。