





JSONデータ圧縮方式をzstdに切り替えデータ量を38.3%削減した事例、及びマイクロサービスの無停止アップデート事例について紹介したいと思います。
はじめに
JPRゲーム事業本部開発基盤部の池田周平です。先日 Rails5対応についてDeNA techブログに投稿 した@namusyakaと同じチームで働いています。
JSON文字列をRDBに格納する際の圧縮フォーマットをSnappyからzstdに切り替え、データ量を削減した事例を紹介したいと思います。本対応を実施した目的はDB負荷対策です。DBで扱うデータをより小さくすることで、DBサーバのDiskI/O負荷とMaster-Slave間のレプリケーション遅延対策を目的としています。
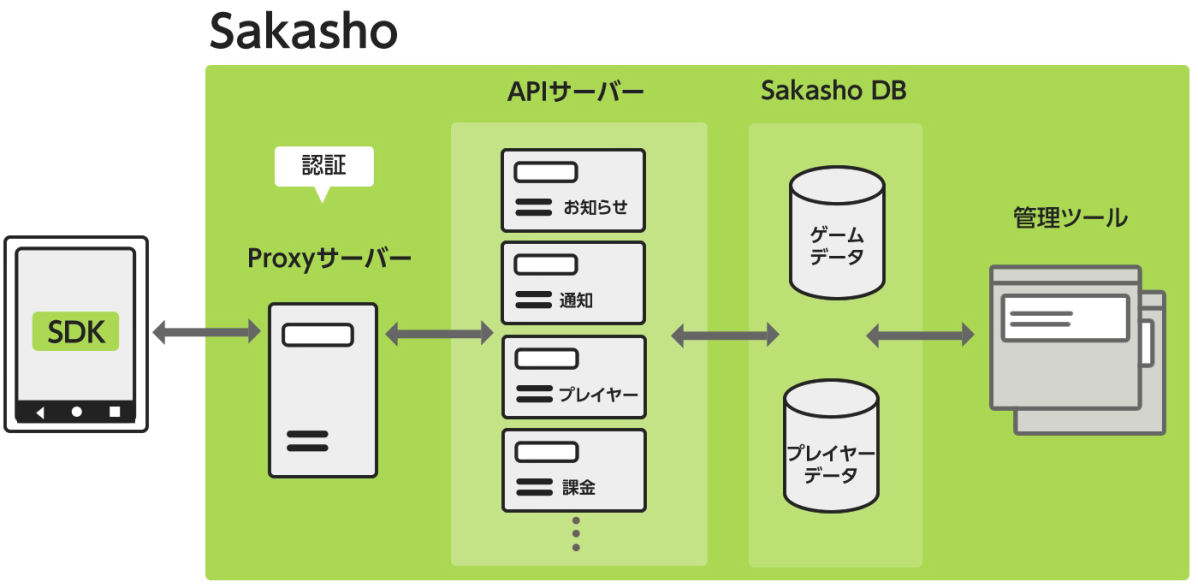
「Sakasho」は、DeNAが持つモバイルゲームのためのプラットフォームです。複数タイトルのゲームを取り扱っており、一部データはゲーム毎の仕様差を吸収し柔軟に取り扱うため、あえてスキーマレスなJSONを採用しています。JSON文字列に圧縮を掛けRDBに保存しているのです。RDBにJSONを格納している狙いはデータ不整合を避けるためで、トランザクションを張りデータ操作しています。
Snappy vs zstd
サンプル数はそれぞれ500万件くらいで、平均6Kbyte 最大2MbyteのJSONデータに対する圧縮時のログを集計して計算しました。結果データ圧縮率はzstdが12.4062% Snappyが20.1272%でした。Snappyからzstdに切り替えた結果データ量が38.3%削減されました。またAPPサーバのCPU使用率は反映前後で変化がなくサーバ追加等の対応は発生しませんでした。
あくまでDeNAで運用しているサービスの1事例です。正確な情報は Zstandard公式ページ をご覧ください。
Snappyとzstdについて
zstd正式名称Zstandardは、Facebookが2016年に公開したBSDライセンスのリアルタイム圧縮アルゴリズムです。リアルタイム圧縮とはデータを高速に圧縮と解凍することに主眼を置いたアルゴリズムであることを意味しています。公式ドキュメントによるとzlibと比較して圧縮率は変わらず、圧縮速度3.9倍、解凍速度2.8倍の性能です。またトレーニング機能を有し、これはデータ毎に固有辞書を生成する機能で、より効率的なデータ圧縮を実現します。
※ 圧縮解凍速度は、 Zstandard公式ページ に公開されているベンチマークデータから計算しました。またSnappyはGoogleが2011年に公開した圧縮アルゴリズムです。
Sakashoとは
Sakashoは、DeNAが持つモバイルゲームのためのプラットフォームです。 モバイルゲームを開発するために必要な機能を一通り提供し、ゲームの開発の効率化を図るための共通基盤として開発・運用されています。マイクロサービス構成となっており、役割ごとに10の独立したサービスと、管理ツールによって構成されています。
マイクロサービスの無停止アップデート
データ圧縮方式をSnappyからzstdに切り替えるにあたり、無停止でアップデートを実施するためにdeploy方法を工夫しました。
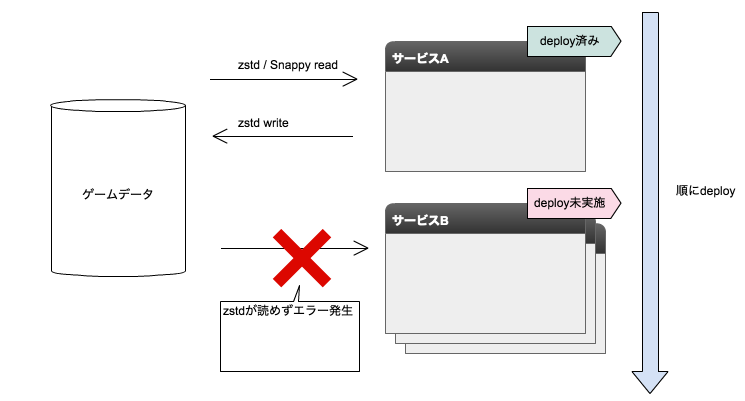
仮にマイクロサービス群に対して順にdeployを行っていくと、後半にdeployするサービスで障害が発生してしまいます。
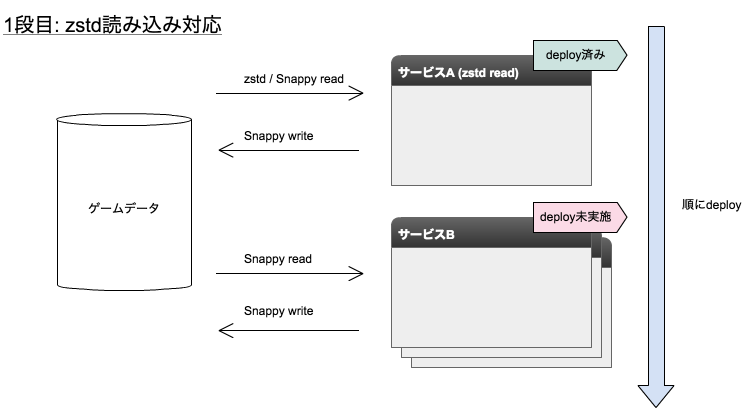
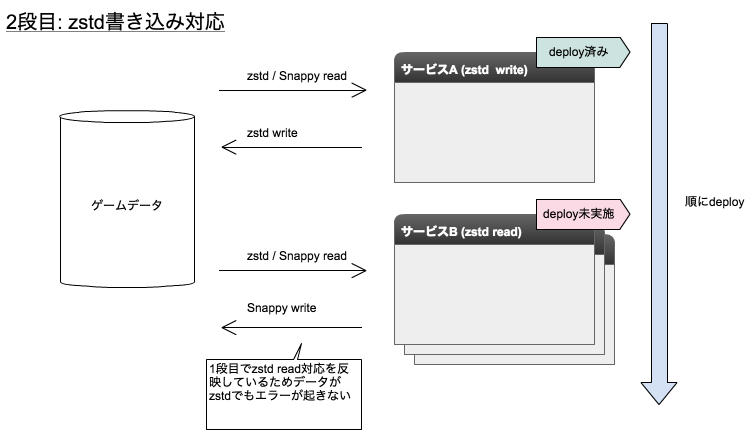
無停止でアップデートするために、下図のようにdeployを2段階に分け、1段目でSnappyとzstdどちらでもデータをreadできる対応をdeployし、2段目でデータ圧縮方式を切り替える対応をdeployすることで複数のマイクロサービスにまたがる修正を本番反映しました。
zstdライブラリの選定
各サービスは主にRubyで開発しています。zstdもRubyから扱う場合がほとんどです。gemに登録されている複数のzstdライブラリのうち、どれを選ぶべきか悩んでいたらruby expertな先輩からnative extentionでビルドしているため、メモリリークの観点で調査するべきだとアドバイスもらいました。
検証結果とコードはこちらです。
## memory_usage_zstd.rb
require 'zstd'
def current_process_memory_usage
`ps ax -o pid,rss | grep -E "^[[:space:]]*#{Process.pid}"`.strip.split.map(&:to_i)[1]
end
JSONFILE_PATH = 'data_139k.json'
json_data = open(JSONFILE_PATH){ |io| io.to_s }
compressed_data = Zstd.new.compress(json_data)
1_000_000_000.times do |n|
Zstd.new.decompress(compressed_data)
puts "loop:#{n} memory usage: #{current_process_memory_usage} Kbytes" if n % 1_000_000 == 0
end
## memory_usage_zstd_ruby.rb
require 'zstd-ruby'
.....
compressed_data = Zstd.compress(json_data)
1_000_000_000.times do |n|
Zstd.decompress(compressed_data)
puts "loop:#{n} memory usage: #{current_process_memory_usage} Kbytes" if n % 1_000_000 == 0
end
## gem: zstd (残念ながらメモリリークした)
## https://rubygems.org/gems/zstd/
$ ruby memory_usage_zstd.rb
loop:0 memory usage: 10884 Kbytes
loop:1000000 memory usage: 43200 Kbytes
loop:2000000 memory usage: 74776 Kbytes
loop:3000000 memory usage: 106692 Kbytes
loop:4000000 memory usage: 138616 Kbytes
loop:5000000 memory usage: 169960 Kbytes
loop:6000000 memory usage: 201592 Kbytes
loop:7000000 memory usage: 233584 Kbytes
loop:8000000 memory usage: 265236 Kbytes
loop:9000000 memory usage: 297132 Kbytes
loop:10000000 memory usage: 329136 Kbytes
## gem: zstd-ruby
## https://rubygems.org/gems/zstd-ruby
$ ruby memory_usage_zstd_ruby.rb
loop:0 memory usage: 10836 bytes
loop:1000000 memory usage: 13060 Kbytes
loop:2000000 memory usage: 13808 Kbytes
loop:3000000 memory usage: 13816 Kbytes
loop:4000000 memory usage: 13944 Kbytes
loop:5000000 memory usage: 13944 Kbytes
loop:6000000 memory usage: 13944 Kbytes
loop:7000000 memory usage: 14176 Kbytes
loop:8000000 memory usage: 14176 Kbytes
loop:9000000 memory usage: 14184 Kbytes
loop:10000000 memory usage: 14184 Kbytes
まとめ
JSONをzstd圧縮してDBに格納したら、Snappyと比較してデータ量が38.3%削減。JSON文字列と比較して87.6%データ削減できました。 Rubyでzstdフォーマットを扱う場合は zstd-ruby がオススメです。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。