





DeNAのOpenStackインフラ運用を担当している窪田です。 最後にご紹介するのはSDS Cephについてです。採用の背景と、これまで運用していく中で直面したパフォーマンスの問題、それをどのようにシューティングしたのかについてご紹介します。
採用の背景
第一回の小野の記事 で、Ceph導入によって実現されたこととして、OpenStackとの連携、ストレージプールの外部化、ライブマイグレーションを取り上げました。実のところこれらのことはCephでなくても近年リリースされている商用ストレージやSDSをうたうプロダクトであれば大抵できることで、これらの実現の他にも重要視していることがありました。 決め手となったのはOSSプロダクトであることです。OSSだとなぜいいのかというと、ソースコードが公開されていることによって、やろうと思えばソフトウェアの振る舞いを詳細に把握することが可能ですし、そうすることでパフォーマンス上のトラブルが起きたときに自力で何がボトルネックとなっているのかを見極め、問題をうやむやにせず納得のいく対応策を練ることができる場合があるからです。これまでDeNAのインフラを運用してきた経験からその重要性を無視できず、中身がブラックボックスなものはできれば避けたいという思いがありました。
構成
本題に入る前に弊社環境の構成について触れておきます。弊社インフラの全てがこの構成で運用しているわけでなく、まだ社内の開発者用のインフラに限定しています。 Cephはブロックストレージ、オブジェクトストレージ、ファイルシステムの三用途に使えますが、弊社ではKVM仮想マシンのストレージとして使うのが目的なのでブロックストレージ機能のみ使っています。 Cephのバージョンは0.94.6のHammerリリースを使っています。最新版ではないのでこれから述べることは最新版では当てはまらない情報も含まれていますがそこはご容赦ください。
個々のサーバのハードウェアとソフトウェアの構成は下図のようになっています。
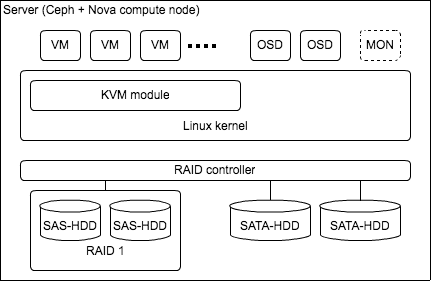
ALL HDDです。ネットワークは物理的に一つのLANに全Ceph nodeがつながっています。 Cephのパフォーマンスをより引き出すには、Ceph nodeのクラスタにそれ専用のサーバを設け、Cephクラスタ内の通信は専用のネットワークを敷く(Cluster Network)など考えられますが、 まずは今あるハードウェア資産を活かして最小限のハードウェアコストで構成し、ボトルネックを見極め、どうしてもハードウェアリソースの増強が必要な場合は追加投資、あるいはCephの導入を見送る選択肢も残しつつ進めていくことにしました。 結果、後述するチューニングを経てこの物理構成を崩さず今に至っています。ですが問題がないわけではありません。ネットワークでいえば輻輳しやすい問題があります。
今はコストを抑えたハードウェア構成を組んでいますが、これで十分と考えているわけでなく、物理的なI/Oの性能が不足しているならSSDを導入することや、後述のfsync/fdatasyncの性能問題のようなCephならではの欠点を補えるようなストレージを導入してマルチバックエンドストレージ構成にするなども視野に入れて検討しています。
ネットワークの輻輳
各Ceph nodeで稼働しているOSDが相互にTCPセッションをはってメッシュ状に通信している上に、Ceph nodeはCompute nodeも兼ねているので、OSDはCephクライアントとなるNova instanceともTCPセッションをはっています。なので各node間の同時通信が発生しやすく、バーストトラフィックによるパケットの廃棄(パケロス)が起きやすい構成です。 パケロスを抑える効果的な手段は、大きなフレームバッファを搭載しているネットワークスイッチを導入する、CephのPublic NetworkとCluster Networkを物理的に分ける、など考えられますが、既存資産を限りなく使い切りたいので、発想を変えてパケロスを抑えるのを諦め、BigSwitchとLinuxのQoS機能を組み合わせ、Nova instanceのトラフィックを優先してユーザ影響を軽減するような仕組みにできないかを検証しています。
パフォーマンスチューニング
上図のようなハードウェア構成でぜひやるべきことが2つあります。
- ジャーナルとデータ領域を一つの物理ディスクに共存させない
- tcmallocのキャッシュサイズを拡張する
Cephは一つのOSDに対して二度の書き込みを行います。一度目がジャーナル領域、二度目がデータ領域です。ジャーナルに書き込まれた時点でOSDはクライアントに書き込み完了のレスポンスを返すことができるので、ジャーナルにSSDのような高速なハードウェアを使う方が良いという話を聞きますが、弊社ではSSDは使わず、4つのHDDを下図のように構成しています。
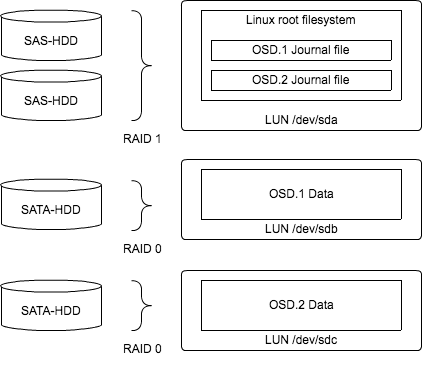
Linuxルートファイルシステムが保存されているディスクは冗長化のためHW RAIDでミラーリング(RAID1)し、同ディスクに全OSDのジャーナルをファイルとして置いた構成です。 ディスクの数にもよりますが、一つのディスクにジャーナルとデータ領域を共存させるよりも、ジャーナルはデータ領域とは物理的に別のディスクを使ったほうがI/Oスループットが向上します。ジャーナルへのI/Oはシーケンシャルwriteなので、ランダムI/O中心のデータ領域と比べてディスクへの負荷が低く、高いIOPSが出やすいです。
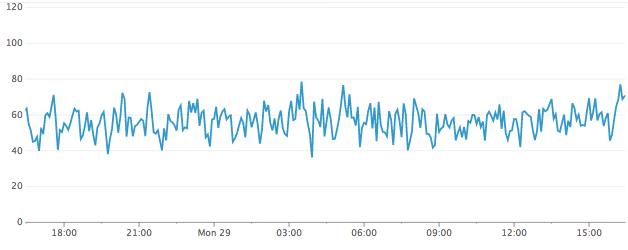
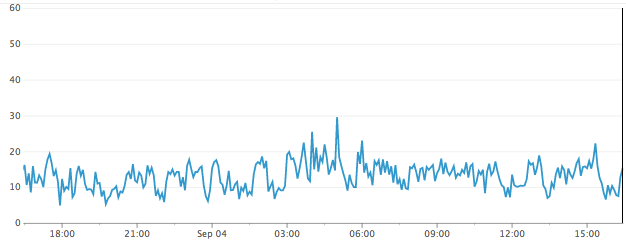
ご参考までに、ディスクの負荷がどの程度改善するのかを、データ領域側ディスクのiostatの%utilをグラフ化したもので比較すると、下のように50%前後で推移していたのが15%前後まで下がりました。
ジャーナルと共存した場合
ジャーナルと共存しない場合
あとこの構成にする上で設定しておくべきこととしてあるのが、ジャーナル側ディスクのLinux I/OスケジューラをDeadlineスケジューラにすることです。その他のI/Oスケジューラだと複数のOSDからくるシーケンシャルwriteを効率良くさばけず、パフォーマンスを維持できないのでDeadlineスケジューラは必須です。
tcmallocのキャッシュサイズを拡張するチューニングについてはCephコミュニティなどからも報告があり、詳細はそちらに譲ります。 tcmallocのキャッシュサイズ拡張は、あらゆるワークロードでパフォーマンスが向上するわけではなさそうですが、弊社環境では劇的な効果がありました。 弊社では前述したように28 Ceph node、56 OSDで約1,500のNova instance(KVM仮想マシン)がCeph上で常時稼働していますが、 Nova instanceが増えるにつれて1 OSDあたりがさばくメッセージ量が増え、tcmallocのキャッシュメモリの獲得、解放にかかるCPU処理が重くなり、 クライアントのI/Oリクエストが数秒から数十秒以上待たされる現象が頻発していたのですが、このチューニングによって秒単位の遅延がほとんど発生しなくなりました。 Cephクライアントを増やしていくとパフォーマンスが劣化するような現象にあたった場合は試してみるとよいでしょう。
ログ分析
パフォーマンスボトルネックの解析で実際に役立ったログの分析方法を一つご紹介します。 CephはI/Oのパフォーマンスが何らかの要因で劣化すると、クライアントからのI/Oリクエストの遅延間隔をログに記録します。slow requestと書かれたログです。弊社では遅延の要因を判断する上でslow requestをよくみています。slow requestのログの末尾にはOSDの何の処理に時間がかかっているのかがマーキングされており、チューニングの判断材料にしています。下記のようなログが書き出されます。
- “currently no flag points reached”
- “currently started”
- “currently waiting for rw locks”
- “currently waiting for subops from "
- “currently commit_sent”
この中でも"currently commit_sent"はあまり深刻に受け止める必要のないログです。このログはジャーナルにwrite済みのデータをデータ領域にwriteするのが遅れていることを示しており、言い換えればジャーナルにデータが何秒滞留しているかを示しています。クライアントへのレスポンスが遅延しているわけではなく、ジャーナルのサイズに余裕がある場合はこのログが断片的に出ても問題ないとみなしており、弊社ではほぼ無視しています。
その他のログは重要です。ここでは"currently waiting for subops from “だけ取り上げてみましょう。 OSDのwrite処理はまずPrimary OSDがクライアントからwriteのメッセージを受けてSecondary OSDとTertiary OSDにwriteメッセージを投げます(レプリケーション数3で運用しています)が、投げたメッセージに対してSecondaryかTertiaryのどちらかのレスポンスが遅れるとこのログが出ます。ログのfromの後ろにSecondaryとTertiaryのIDが入るのでどのSecondaryまたはTertiaryかは特定できます。なのでこのログが出たときはログを出しているPrimaryに遅延の原因があるわけでなく、そのOSDとレプリケーションを組んでいるSecondaryかTertiaryのどちらかに原因があるはずです。
他にもslow requestのログに含まれる情報で役に立つものとしてRBD imageのIDがあります。RBD imageはCinder volumeでもあるので、どのCinder volumeのI/Oが遅延しているのかを特定できます。
fsync問題
前述のチューニングである程度パフォーマンスは改善するのですが、それでもなお課題として残っているのがfsync/fdatasyncシステムコールを多用するwrite処理が苦手なことです。そのようなアプリケーションで例をいえばMySQLのトランザクションのコミット処理が当てはまります。 なぜ苦手なのかというと、Cephは複数のI/Oを同時並行処理するようなワークロードが得意ですが、fsyncのようなデータ同期を挟まれてしまうと後続のwriteが待たされてしまいます。図にするとこのようなイメージです。
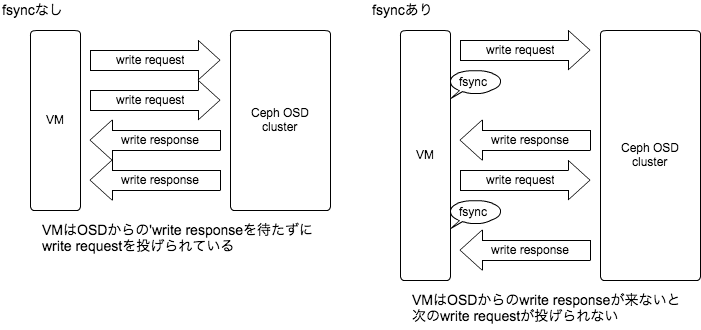
Cephのようにネットワークまたぎで同期レプリケーションまでやるストレージだと、サーバローカルのストレージへのI/Oで完結する場合に比べてどうしてもレイテンシが長くなり、fsyncによるレスポンス待ちの影響が際立ちます。
弊社ではこの問題の根本解決は現状無理だと判断し、クライアントのローカルファイルシステム(ext4やxfs)のバリアオプションを無効にすることでfsyncによるパフォーマンスの劣化を抑えています。バリアオプションを無効化すればfsyncによるデータ同期を回避でき、同時並行writeを維持しやすく、writeレスポンス待ちの影響を軽減できます。ただしバリアオプションの無効化には副作用があり、リスクを許容できるかを検討した上で使う必要があるのでご注意ください。弊社では前述したように社内の開発者向け環境で、最悪、データが一部欠損するようなことがあっても大きな問題にはならないようなものなどに限定して使っています。
まとめ
Cephのパフォーマンスチューニングにフォーカスしてこれまで取り組んできたことをいくつかご紹介しました。冒頭でCephの良さの一つにソースコードが公開されていることをあげましたが、ここでご紹介したパフォーマンス問題の解析でもそれが大いに役立ってくれました。まだまだCephの運用経験が浅く、わかってないことも多いのですが、今後も経験を積むことで理解がどこまでも深まっていくと思います。この記事でCephを使ってみたくなった方が少しでも増えればと思っています。
最後に
DeNAのOpenStackインフラについて三回にわたってご紹介しましたがいかがでしたでしょうか。 宣伝ですが、2017年2月10日(金) に DeNA TechCon 2017 が開催されます。OpenStackに関するセクションも予定しており、ブログでご紹介しきれなかった内容もお話できればと思っているのでぜひご参加ください。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。