





このブログは「mobage developers blog」2016.8.3の記事を転載させていただきました。
こんにちは、IT基盤部の原田です。
前回は インフラの体制 / 概況、サーバの構築、キャパシティプランニングについて触れました。第2回となる今回は、性能劣化や障害発生時に私達が利用しているプロファイリングツールの紹介をしていきます。
サーバ運用するにあたり、どれだけ完璧なサーバ群を準備したとしても、アプリケーションのバグや急激なトラフィックの高騰等によって障害は起こりますし、パフォーマンス劣化も容易に起こり得るものです。
DeNAのインフラ運用では、構築したサーバをゲーム開発側にはいどうぞと渡して終わりではなく、乗っているアプリケーションのプロファイリングまで実施します。障害やパフォーマンス劣化が起きたときは原因箇所の究明まで行い、ゲーム開発側の改善のお手伝いをします。
今回は障害が起きたときの原因調査のためにDeNAが使用しているツールを一部紹介をしていきます。
紹介ツール一覧
| 言語 | ツール | 概要, 用途 |
|---|---|---|
| Perl | perlstack | ・負荷の低いスタックトレース取得ツール ・稼働中Perl webappの恒常的なトレース取得に利用 |
| gdbperl | ・詳細なスタックトレース取得ツール ・batch等遅くなっても問題ないものや詳細な調査の際に利用 | |
| phs (perl heap stat) | ・ヒープ情報取得ツール ・Perl webapp の memory 消費の原因の調査に利用 | |
| NYTProf | ・プロファイラツール ・性能劣化調査に利用 | |
| Ruby | gdbruby | ・詳細なスタックトレース取得ツール ・batch等遅くなっても問題ないものや詳細な調査の際に利用 |
| stackprof | ・プロファイラツール ・性能劣化調査に利用 |
Perl
まずはPerlアプリケーションの調査ツールを紹介していきますが、説明のため下記のような簡単なPerlサンプルアプリケーションを用意しました。
sample app
#!perl
sub main_proc {
my ($int) = @_;
print `date`;
sleep $int;
}
sub mainloop {
while (1) {
main_proc(1,"dummy_argument");
}
}
mainloop();
perlstack
実行中のperlプロセスのperl stackを取得してくれるツールです。実装としてはptraceでプロセスにアタッチして情報を取得するものになります。
perlstackは、本番稼働中の全プロセスにアタッチしても性能低下は見えない程度の負荷なので、本番稼働中の一部サーバで常時取得してロギングしています。
実行イメージ
$ sudo perlstack 29146 29146 /home/game/daemon.pl:17 # sleep()が対応 /home/game/daemon.pl:10 # main_proc()が対応 /home/game/daemon.pl:9 # while loopが対応 /home/game/daemon.pl:20 # mainloop()が対応 ```
典型的なWebAppでの実行結果例
アクセスがない時間帯
25413,25429,25474,25519,25549,25593,25630,25670,25713,25742,25794,25824,25869,25943
/home/game/fcgi/index.fcgi:68 # accept()を呼んでる箇所
/home/game/fcgi/index.fcgi:66
/home/game/fcgi/index.fcgi:50
多数のworkerがaccept()を呼べている状態であり、余裕のある状態であると判断できます。
DBアクセスの多い時間帯
21188,21209,21246,21275,21320,21357,21395,21440,21501,21559,21595,21630,21672,21700 # 多くのプロセス
/usr/dena/home/infra/perlbrew/perls/perl-5.16.1/lib/site_perl/5.16.1/x86_64-linux/DBD/mysql.pm:152 # DBアクセス
/usr/dena/home/infra/perlbrew/perls/perl-5.16.1/lib/site_perl/5.16.1/x86_64-linux/DBI.pm:658
/usr/dena/home/infra/perlbrew/perls/perl-5.16.1/lib/site_perl/5.16.1/x86_64-linux/DBI.pm:727
...
DBへのアクセス箇所にプロセスが集中している状態で、これが酷くなると障害につながってきます。
gdbperl
実行中のperlプロセス or coreのPerl stack, C stackを出力するツールです。
https://github.com/ahiguti/gdbperl
実装としてはgdbでアタッチ->Perlデータ構造をCレベルで辿ってPerlレベルのスタックを出力する作りになっています。gdbでアタッチしているため少し遅いですが、Perlの引数も取得出来るため詳細な調査をしたいときに有効です。
実行例
$ sudo gdbperl.pl 29146 ... c_backtrace: #0 0x00000034f70aca20 in __nanosleep_nocancel () from /lib64/libc.so.6 ... #6 0x000000000040181c in main ()perl_cur_op: /home/game/daemon.pl:17(main)
perl_backtrace: [3] /tmp/daemon.pl:10(main) -> main::main_proc ARGS: (1, “dummy_argument”) # 引数が見える [2] /tmp/daemon.pl:9(main) -> (loop) [1] /tmp/daemon.pl:20(main) -> main::mainloop ARGS: ()
phs (perl heap stat)
webapp workerにおけるメモリ消費の原因を探るために使用するツールです。
一般的に「どこでメモリの大量消費があったか」を事後に知る事は困難です。そのため、実行時にメモリ消費のログを取得しておき後から分析出来るようにしています。
実装としてはLD_PRELOADでmallocその他メモリ管理部分の関数を上書いています。
上書き内容としては図の右側のようなイメージで、中でオリジナルのmallocを呼び出した後にログに書きだすなりバックトレースを保存するなり、やりたい処理を行いポインタを返す、という処理になっています。
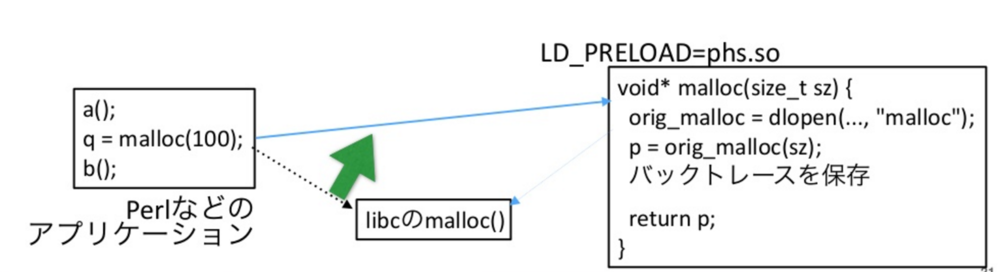
ログとしては2種類吐いており、1つが短時間で大量のヒープ拡張/縮小を検知した時、(EXTEND/SHRINK)にPerl/CのstacktraceおよびRequest URIを、もう1つがプロセス終了時に各コード箇所が消費しているPerlオブジェクトのヒープ使用量を出力しています。
実行例(その1)
PHS: EXTEND now=1465820646.073279 cur=2003819 prev=1000000 u=841986608,105936 /usr/share/perl5/site_perl/5.8.8/Class/Accessor.pm:13;…(とても長いので省略)…;/home/game/script/infra/fcgi/mobage_fcgi_starter.pl:143 REQUEST_URI=/xxx?yyy=zzz
ヒープサイズが特定のRequest URIによって1000000から2003819に肥大した事が分かります。
実行例(その2)
PHS: /…/Battle.pm:834;/…/Controller.pm:767;/…/Main.pm:640 8 1 8 PHS: /…/Battle.pm:836;/…/Controller.pm:767;/…/Main.pm:640 64 1 64 PHS: /…/Battle.pm:837;/…/Controller.pm:767;/…/Main.pm:640 17 1 17 PHS: /…/Battle.pm:838;/…/Controller.pm:767;/…/Main.pm:640 8 1 8 PHS: /…/Battle.pm:839;/…/Controller.pm:767;/…/Main.pm:640 16 1 16
1行目はMain.pm:640->Controller.pm:767->Battle.pm:834で確保された領域が8バイトであることを示しています。ただこの実行例(その2)についてはログがあまりに長大なため、怪しい部分を探るときは、コード箇所ごとに消費メモリを足し上げてsortして結果を見ます。
整形した後の結果
25039579 TOTAL _exit 1567552 /…/Base.pm:35;/…/Redundant.pm:45;/…/Cache/Local.pm:81 1321066 /…/DBI.pm:256;/…/DBD/mysql.pm:793;/…/DBI.pm:1641 758848 /…/Text/Xslate.pm:504;/…/Xslate.pm:91;/…/Response.pm:565
NYTProf
こちらはPerlでは定番の構成のプロファイラツールです。性能問題の多くはこれを見て解決します。ただNYTProfは性能劣化があるため、DeNAでは1系統に1サーバだけ仕込み、かつ複数workerがあっても一部workerに絞って取得しています。こちらはHTML化して、開発者も簡単に見れるような仕組みを作って利用しています。
Ruby
次に、弊社でも増えてきたRuby案件用に用意したRubyアプリケーション調査ツールを紹介していきます。Perl同様簡単なRubyサンプルアプリケーションを用意しました。
sample app
def mainloop() while true do main_proc(2, “dummy_arg”) end enddef main_proc(interval, dummy) sleep(interval) end
mainloop()
$ sudo ./gdbruby 8861 c_backtrace: #0 0x00007ff9f5fb075b in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 … #12 0x00007ff9f640594b in main (argc=2, argv=0x7fff6c237138) at main.c:36ruby_backtrace: [4] sleep() <- /tmp/daemon.rb:10 [3] main_proc() <- /tmp/daemon.rb:10 [2] mainloop() <- /tmp/daemon.rb:5 [1] <main>() <- /tmp/daemon.rb:13
stackprof
Rubyで現時点でおそらく一番高性能と思われるプロファイラツールです。
https://github.com/tmm1/stackprof
NYTProfと同様に1系統に1台、worker数も絞って取得しています。
まとめ
- DeNAのインフラでは、性能劣化や障害時に原因究明のためアプリケーションのプロファイリングも行っている
- ケースや言語によって様々なツールを使い分けてプロファイリングを実施している
次回はDeNAで現在利用しているクラウド環境のちょっとした運用Tipsについて触れたいと思います。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。